- Français
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Comment fonctionnent les dispositifs IoT : architecture, composants et facteurs de performance
Catalogue
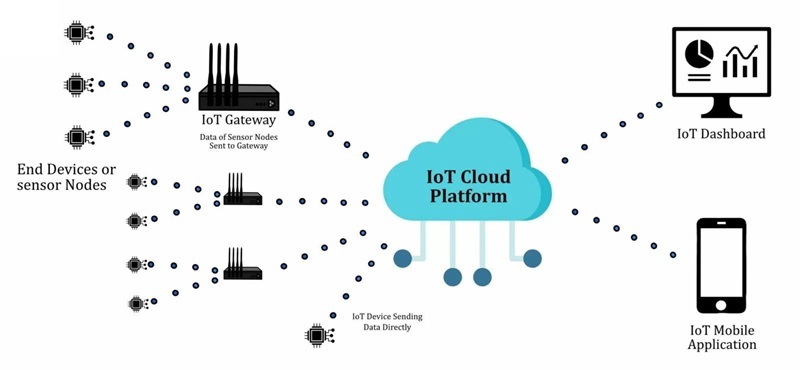
Comment fonctionne un dispositif IoT
Un produit IoT est plus facile à comprendre lorsqu'il est traité comme une boucle fermée et mesurable : il observe le monde physique, convertit ce qu'il a observé en données que l'électronique peut traiter, déplace ces données vers un endroit où elles peuvent être interprétées, puis déclenche une réponse. Beaucoup d'équipes commencent par poursuivre la « connectivité », et c'est compréhensible, les démonstrations ont l'air excellentes lorsque le tableau de bord se met à jour en temps réel, mais sur le terrain, le dispositif est jugé selon qu'il se comporte de la même manière au jour 3, jour 30 et jour 300.
La boucle doit survivre aux contraintes quotidiennes qui tendent à se manifester aux pires moments : puissance limitée, latence imprévisible, interférences, plafonds de coûts et attentes de sécurité évolutives. Lorsque la boucle est conçue en tenant compte de ces contraintes, les couches réseau et cloud semblent être une extension propre du produit plutôt qu'une source de surprises et de cas limites fragiles.
Sens : transformer un signal physique en un signal électrique
À la périphérie, un capteur convertit une variable du monde réel en une représentation électrique que le dispositif peut mesurer. La variable peut être environnementale, mécanique ou électrique, et le travail du capteur consiste à créer un signal qui reste interprétable malgré les variations de température, la vibration et la variabilité de l'installation.
Variables du monde réel couramment mesurées :
• Température
• Vibration
• Pression
• Lumière
• Mouvement
• Courant
• Concentration de gaz
La sortie du capteur se classe généralement dans l'une de deux catégories, et le choix affecte tout ce qui suit (conception avant, échantillonnage et tolérance au bruit).
Types de sortie de capteur courants :
• Analogique : une tension ou un courant variant de façon continue
• Numérique : des lectures encapsulées via I²C/SPI/UART
En dehors des conditions de laboratoire, la précision de la mesure dépend de plus que du capteur lui-même. Les facteurs d'installation tels que le placement, la force de montage, le flux d'air, les sources de chaleur à proximité, le routage des câbles et le couplage mécanique peuvent affecter considérablement les résultats.
Les erreurs de mesure sont souvent causées par des problèmes d'installation plutôt que par des défauts du capteur. Des surfaces de montage flexibles ou des structures résonnantes peuvent déformer les données et créer des lectures trompeuses. Considérer le montage et la conception mécanique comme faisant partie du système de mesure aide à réduire le temps de dépannage et améliore la fiabilité des mesures.
Condition : avant de ligne analogique (AFE) et hygiène du signal
De nombreux dispositifs acheminent les sorties brutes des capteurs à travers un avant de ligne analogique (AFE) avant de numériser. Cette étape façonne discrètement si le reste du système fonctionne avec un signal stable et fiable ou avec quelque chose qui ne se comporte que dans des conditions contrôlées.
Fonctions typiques de l'AFE :
• Polarisation et génération de référence pour maintenir les signaux à l'intérieur de la plage d'entrée valide de l'ADC
• Amplification (amplificateurs d'instrumentation, stades de gain) pour rendre les petits signaux mesurables
• Filtrage (filtrage passe-bas, filtrage anti-aliasing) pour réduire le bruit et limiter un contenu haute fréquence trompeur
• Protection (structures ESD, protection contre les surtensions, serre-fils d'entrée) pour survivre aux erreurs de câblage et de manipulation
Les environnements opérationnels réels introduisent souvent des sources de bruit telles que des moteurs, des câbles longs, des régulateurs de commutation et des radios à proximité. Ces effets peuvent créer des erreurs de mesure qui peuvent sembler aléatoires jusqu'à ce que la source soit identifiée.
Une bonne mise à la terre, un blindage approprié et un filtrage anti-aliasing de base améliorent souvent la qualité du signal plus efficacement que de se fier uniquement à un filtrage logiciel complexe. S'attaquer au bruit à la source produit généralement des mesures et des performances système plus fiables.
Convertir : Échantillonnage ADC avec des compromis intentionnels
Lorsque le signal est analogique, un ADC le convertit en échantillons numériques. La conversion elle-même est simple ; ce qui nécessite souvent de l'expérience, c'est de choisir des paramètres d'échantillonnage qui se comportent bien sous les limites réelles de la batterie et du réseau.
Deux choix d'échantillonnage qui façonnent le comportement en aval :
• Taux d'échantillonnage : suffisamment rapide pour capturer le phénomène, mais pas trop rapide pour ne pas consommer d'énergie et produire des données inutiles
• Résolution : suffisamment fine pour détecter un changement significatif sans transformer le bruit et la dérive en une précision fallacieuse
L'échantillonnage fonctionne mieux lorsqu'il est considéré comme une décision au niveau du système plutôt que comme une spécification isolée. Le suréchantillonnage peut silencieusement forcer plus d'activité radio (et le temps radio est souvent ce qui épuise la batterie en premier). Le sous-échantillonnage peut manquer des événements courts et opérationnellement significatifs, des pics de pression, des impacts, des pauses brèves, que les utilisateurs se rappellent parce qu'ils représentaient le moment où quelque chose a mal tourné.
Calculer : Traitement des microcontrôleurs, synchronisation et logique de bord
Un microcontrôleur (MCU) lit généralement les données des capteurs selon un calendrier discipliné utilisant des minuteries, des interruptions et DMA afin que le timing de l'appareil reste cohérent même lorsque le firmware s'agrandit. Un timing cohérent est l'un de ces détails qui semble ennuyeux jusqu'au jour où vous déboguez un problème sur le terrain et réalisez que le « signal » était en réalité un fluctuation de planification.
Tâches de traitement courantes côté MCU :
• Filtrage numérique (moyenne mobile, médiane, IIR) pour réduire le jitter et les valeurs aberrantes
• Calibration et compensation (correction de décalage, compensation de température, linéarisation)
• Évaluation des règles (seuils, hystérésis, suppression de rebond) pour éviter un basculement instable
• Analytique de bord légère (extraction de caractéristiques, notation d'anomalies, compression) pour réduire la bande passante et le calcul dans le cloud
Une approche de conception utile consiste à séparer les données de mesure de la logique de décision. Les lectures des capteurs peuvent fluctuer en raison des conditions physiques normales, tandis qu'un comportement système stable peut être maintenu par le biais de l'hystérésis, des fenêtres de synchronisation et du contrôle de machine à états. Cette séparation aide à réduire les fausses alertes, améliore la stabilité du système et empêche les indications de défaut incorrectes lorsque des variations de mesure temporaires se produisent.
Toutes les décisions ne bénéficient pas d'un délai dans le cloud. Certaines actions sont sensibles au temps ou orientées vers l'évitement de dommages, et les déléguer au cloud tend à créer des modes de défaillance inconfortables lorsque le réseau est lent ou absent.
Exemples souvent gérés localement :
• Coupure de surintensité ; protection contre la surchauffe ; détection de blocage du moteur
Le cloud tend à briller lorsque la tâche bénéficie d'un contexte plus large ou d'horizons temporels plus longs.
Catégories de décisions côté cloud :
• Analyse de tendance à long terme et maintenance prédictive
• Corrélation inter-appareils
• Mises à jour des modèles et changements de politique à l'échelle de la flotte
Une règle pratique sur laquelle les équipes convergent souvent est simple : si un ordre retardé peut plausiblement entraîner des dommages, l'appareil doit d'abord se protéger et rapporter ensuite. Cette approche semble généralement conservatrice de manière positive, surtout lorsque vous êtes celui qui est de garde pendant une panne de réseau.
Communiquer : Liens radio/câblés et protocoles d'application
La couche de communication déplace la télémétrie vers un téléphone, une passerelle ou un point de terminaison dans le cloud. Choisir une technologie de lien dépend moins de ce qui est tendance et plus de ce qui correspond à l'environnement physique, au modèle de déploiement et au budget énergétique.
Options de connectivité courantes :
• Wi‑Fi ; BLE ; Zigbee/Thread ; cellulaire (LTE-M/NB-IoT) ; Ethernet
Au-dessus de la couche de lien, les appareils utilisent des protocoles d'application pour structurer et livrer des messages. Le bon protocole dépend généralement de la nécessité pour le produit de disposer d'une télémétrie en streaming, de flux de configuration ou de compatibilité avec l'infrastructure d'entreprise existante.
Protocoles d'application courants :
• MQTT
• HTTP
Les déploiements réels offrent rarement une connectivité stable. Les points d'accès redémarrent, les passerelles disparaissent, la couverture cellulaire fluctue et les interférences apparaissent et disparaissent. Les appareils paraissent beaucoup plus fiables lorsqu'ils peuvent mettre en mémoire tampon les données, réessayer avec parcimonie (et non de manière à saturer le réseau), et maintenir un comportement de dernier état connu clair afin que le système reste compréhensible lorsque les liens sont imparfaits.
La télémétrie est généralement protégée par TLS pour garantir la confidentialité et l'intégrité. Dans de nombreux produits, le premier succès en matière de sécurité consiste simplement à activer le chiffrement partout, mais une sécurité durable va plus loin en rendant l'identité et les mises à jour gérables tout au long de la vie de l'appareil.
Éléments de sécurité courants :
• Identités uniques des appareils et authentification basée sur des certificats
• Stockage sécurisé des clés (éléments sécurisés ou zones de confiance MCU)
• Microprogramme signé et démarrage sécurisé pour réduire le risque d'exécution de code non autorisé
Il y a un schéma que les équipes expérimentées reconnaissent (souvent après l'avoir appris à leurs dépens) : le travail de sécurité est beaucoup moins douloureux lorsque l'identité, la gestion des clés et les chemins de mise à jour sont conçus dès le début. Lorsque ces fondations sont planifiées dès le départ, l'appareil a tendance à rester fonctionnel pendant des années, et pas seulement jusqu'à la première mise à jour majeure sur le terrain.
Cloud et données
Dans le cloud (ou sur une plateforme sur site), les données sont stockées, souvent dans des systèmes en séries temporelles, puis agrégées et analysées. Le cloud est l'endroit où la télémétrie brute peut être transformée en résultats sur lesquels quelqu'un agira réellement, que ce quelqu'un soit un utilisateur, un opérateur ou un moteur de politique automatisé.
Sorties courantes du cloud :
• Alertes (ruptures de seuil, détection de pannes)
• Prévisions (durée de vie utile restante, détection de dérive)
• Tableaux de bord (KPI, tendances, état de santé de la flotte/appareil)
• Commandes de contrôle (points de consigne, plannings, actions activer/désactiver)
La valeur du cloud est plus facile à saisir lorsque les équipes décident à l'avance quelles décisions les données sont censées soutenir. Sans cette discipline, la télémétrie a tendance à devenir un bruit de fond coûteux, collecté de manière fiable, stocké avec diligence, et rarement utilisé avec assurance.
Actionner : Exécution des commandes de manière sécurisée et répétable
Les commandes renvoyées à l'appareil entraînent les actionneurs, et cette partie de la boucle est où la réalité matérielle devient bruyante. L'actionnement nécessite une circulation de conducteur adaptée à la charge, et bénéficie de garde-fous qui rendent les pannes prévisibles plutôt que chaotiques.
Actionneurs courants :
• Moteurs
• Vannes
• Relais
• Chauffages
• LEDs
• Haut-parleurs
Éléments de conduite et de protection courants :
• MOSFETs ; relais ; ponts en H ; triacs (selon les caractéristiques de charge)
• Diodes de retour et snubbers (pour les charges inductives)
• Détection de courant et protections thermiques
• Vérification de l'état lorsque disponible (interrupteurs de fin de course, rétroaction de position, signatures électriques)
Un état d'esprit de fiabilité qui tend à donner des résultats est de supposer que l'actionnement est là où le risque se concentre. Les capteurs échouent souvent silencieusement ; les actionneurs peuvent échouer de manière à ce que les utilisateurs s'en aperçoivent immédiatement. Des sauvegardes simples, des temporisations, des verrouillages, des vérifications de bonne santé empêchent fréquemment les problèmes en cascade et rendent le système plus digne de confiance lors des inévitabilités étranges aux limites.
La boucle se répète
Ce cycle de sens ; calculer, communiquer, actionner se répète continuellement. Localement, il peut s'exécuter en millisecondes ; un aller-retour dans le cloud peut prendre des secondes en fonction du réseau et de la charge du backend. De bons produits considèrent le timing et l'énergie comme des entrées de conception qui façonnent chaque autre décision, plutôt que comme des réflexions après coup à optimiser à la fin.
Stratégies courantes au niveau système :
• Utiliser le traitement en périphérie pour réduire les transmissions inutiles
• Regrouper et compresser la télémétrie lorsque la tolérance à la latence le permet
• Dormir de manière agressive et se réveiller de manière prévisible sur les appareils alimentés par batterie
• Maintenir un « comportement minimum viable » même lorsque le cloud ne peut pas être atteint
Un appareil IoT durable n'est pas défini par un seul composant. Il est défini par la façon dont l'ensemble de la boucle réagit calmement lorsque la réalité s'écarte du plan : signaux bruyants, réseaux intermittents, matériel vieillissant et comportement utilisateur imprévisible. Concevoir en tenant compte de ces conditions fait souvent la différence entre une démonstration qui fonctionne une fois et un produit qui reste serein année après année.
Composants électroniques sur la performance des dispositifs IoT
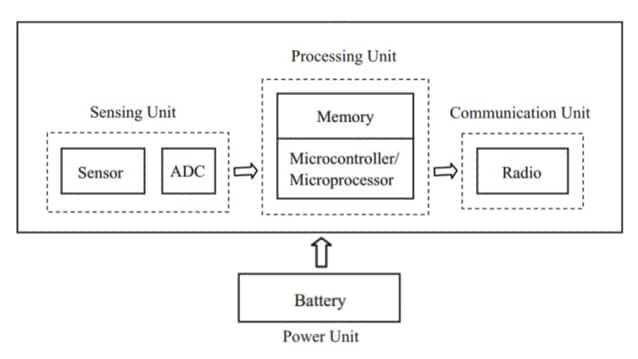
Le matériel IoT a tendance à sembler fiable uniquement lorsque les entrées de capteur, le calcul, le stockage, la distribution d'énergie et la connectivité sont configurés comme un chemin continu de signal et d'énergie.
Une lecture de capteur reste rarement significative si la tension de référence change, si l'horloge fluctue ou si le chemin de données perd occasionnellement des octets sous charge. Un lien radio reste rarement utilisable si l'alimentation baisse pendant les rafales de transmission, si l'oscillateur est bruyant ou si la gestion des identifiants est incohérente lors des réinitialisations.
De nombreuses équipes apprennent que la fiabilité s'améliore souvent davantage en resserrant les frontières entre blocs qu'en ajoutant une autre fonctionnalité : des rails prévisibles, un temps limité, un couplage de bruit contrôlé et un comportement défaillant qui est compréhensible lorsqu'un élément échoue.
L'objectif de conception n'est pas « des pièces parfaites », mais des interfaces qui se comportent de la même manière sur un banc de développeur, lors de déploiements pilotes et des mois plus tard sur le terrain.
Capteur
Les capteurs convertissent les conditions du monde réel en signaux électriques, mais le comportement des produits au quotidien est façonné par des détails qui peuvent sembler petits jusqu'à ce que les données de terrain les rendent indéniablement grands.
Le bruit, le dérive, le montage, le flux d'air, la condensation et le routage des câbles ont tous tendance à transformer un graphique de laboratoire propre en distributions désordonnées auxquelles le micrologiciel doit survivre.
La plage et la résolution doivent s'adapter à la décision qui est prise, et non à une spécification principale. Des configurations trop sensibles amplifient souvent le bruit et le dérive, ce qui tend à augmenter les faux positifs et augmente discrètement le temps de calcul et le temps d'antenne radio. Une plage la plus étroite possible peut sembler défendable lors des revues de conception, mais le comportement sur le terrain favorise souvent une plage légèrement plus large qui produit des mesures plus stables et plus interprétables. Si un modèle ou un seuil en aval va de toute façon lisser les données, pousser la sensibilité brute trop loin peut sembler satisfaisant au début puis frustrant lorsque les tickets de support arrivent.
Le dérive, le vieillissement et l'exposition déterminent si les mesures restent crédibles après quelques mois ou années.
L'étalonnage fonctionne généralement mieux lorsqu'il est considéré comme une routine de cycle de vie plutôt que comme un seul rituel en usine que tout le monde espère d'une tenue éternelle.
• Étaloannage en usine avec coefficients stockés.
• Déclencheurs de recalibrage sur le terrain (prévu, basé sur des événements ou assisté par un technicien).
• Routines d'auto-vérification qui signalent les valeurs aberrantes, le clipping et la saturation.
Les équipes visant à offrir des produits réparables mettent souvent de côté une mémoire flash et un calcul modestes pour les métadonnées d'étalonnage, la traçabilité et les vérifications de cohérence, car c'est moins cher que d'expliquer des lectures incohérentes après le déploiement.
La sélection du taux d'échantillonnage devient généralement une négociation entre la physique, la batterie et l'utilité des données. Échantillonner trop lentement risque l'aliasing et des événements manqués, ce qui peut être difficile à diagnostiquer car les données semblent encore plausibles. Échantillonner trop rapidement augmente la consommation d'énergie et le volume de données, et cela peut créer l'illusion d'une meilleure compréhension sans améliorer matériellement les décisions.
Un schéma qui se maintient bien consiste à capturer le phénomène avec suffisamment de marge, à filtrer tôt (analogique lorsque cela aide réellement, numérique lorsque cela est suffisant) et à réduire le nombre d'échantillons pour le reporting.
Cela produit souvent de meilleurs résultats en matière de batterie que d'échantillonner de manière agressive en espérant que l'analyse dans le cloud compense plus tard.
La nécessité d'un ADC externe dépend généralement de la résolution, de l'impédance d'entrée, de la stabilité de référence et de la tolérance au bruit. Les ADC intégrés aux MCU fonctionnent souvent bien pour la détection de résolution moyenne, tandis que les signaux de précision punissent souvent un agencement et des choix de référence peu rigoureux.
• Sélection de référence à faible bruit et routage de référence.
• Stratégie de mise à la terre, pistes de protection et contrôle du chemin de retour.
• Blindage et routage intentionnel des câbles près des connecteurs.
• Protection ESD placée là où elle intercepte réellement la transitoire.
De petits changements dans le PCB peuvent réduire mesurablement le jitter et améliorer la répétabilité, en particulier pour les sources à haute impédance ou les signaux analogiques de faible niveau où « presque acceptable » devient visiblement instable dans les données de production.
Microcontrôleur (MCU)
Le MCU agit comme le centre opérationnel : il lit les capteurs via GPIO, I²C, SPI et UART ; conditionne les signaux ; exécute l'inférence lorsque cela est applicable ; gère les modes d'alimentation ; et drive les sorties.
Lorsque le comportement du MCU est prévisible, l'ensemble de l'appareil se sent calme ; lorsqu'il ne l'est pas, les pannes semblent souvent aléatoires même lorsque la cause est déterministe.
Un micrologiciel stable provient généralement de machines d'état explicites et d'un timing ayant des limites claires. Les conceptions basées sur des événements utilisant des interruptions, DMA et minuteries surpassent généralement les boucles de sondage en matière de réactivité et d'énergie, surtout dans les dispositifs qui s'endorment souvent.
Lorsque les équipes décrivent des blocages aléatoires, le coupable est souvent l'un de quelques récidivistes : un travail non borné à l'intérieur d'une interruption, un blocage sur bus partagé, une inversion de priorité ou une fragmentation de mémoire qui n'a jamais été stressée sous de longues périodes d'activité.
La planification de la RAM et de la flash fonctionne mieux lorsqu'elle inclut ce qui se passe après que la première démo réussit.
• Tampons réseau et surcharge TLS (y compris le comportement de poignée de main dans le pire des cas).
• Journaux, métriques et dumps de plantage que les ingénieurs demanderont plus tard.
• Espace de mise en scène OTA, plus des métadonnées pour les vérifications d'intégrité.
• Élargissement des fonctionnalités qui arrive de manière prévisible après les retours des pilotes.
La mémoire sous-dimensionnée reste souvent silencieuse au début puis devient douloureuse plus tard, juste au moment où les diagnostics et la sécurité des mises à jour deviennent les principaux outils pour contrôler les risques sur le terrain.
Les appareils devant être fiables bénéficient généralement d'un démarrage sécurisé, d'un stockage de clés protégé, d'une accélération de cryptographie matérielle et d'un générateur de nombres aléatoires véritable. De l'expérience de déploiement, les réajustements de sécurité tendent à être inconfortables car ils entrent en conflit avec les contraintes matérielles expédiées et les identifiants à long terme.
Sélectionner un MCU (ou ajouter un élément de sécurité) qui prend en charge une forte identité et un démarrage mesuré réduit souvent la quantité de logiciel astucieux nécessaire pour compenser des racines de confiance faibles.
L'accès pour SWD/JTAG et la testabilité pratique décident généralement si la fabrication précoce est contrôlée ou chaotique.
• Planification d'accès SWD/JTAG et stratégie de verrouillage pour la production.
• Trous d'essai et disposition favorable aux sondes pour des fixtures à haut volume.
• Points de sens de rails d'alimentation et nœuds mesurables pour un tri rapide.
Une petite quantité d'infrastructure de test peut épargner aux équipes des semaines de conjectures inconfortables lorsque le premier gros lot expose des cas limites qui n'étaient jamais apparus sur des prototypes construits à la main.
Modules de Communication
Le module de communication façonne plus que le budget de liaison : il influence le provisionnement, le comportement de mise à jour, les flux de support et un nombre surprenant de modes de défaillance.
Dans les dispositifs alimentés par batterie, le comportement radio domine souvent la consommation d'énergie, donc les décisions de connectivité tendent à devenir des décisions sur la durée de vie de la batterie sous un autre jour.
La sélection équilibre généralement la portée, la latence, le débit, la topologie et le budget énergétique, avec un regard franc sur les frottements opérationnels.
• BLE pour la courte portée, faible consommation et l'intégration avec les smartphones.
• Wi‑Fi pour un débit plus élevé avec un courant de crête plus élevé et des exigences d'intégrité de puissance plus strictes.
• Thread/Zigbee pour les réseaux maillés et les déploiements à faible consommation à domicile/industriels.
• LoRaWAN pour de longues distances, faibles débits de données et discipline stricte des charges utiles.
• LTE‑M/NB‑IoT pour une couverture étendue avec des contraintes d'opérateur et un provisionnement plus complexe.
Les équipes ressentent souvent un soulagement une fois qu'elles admettent que le « choix de radio » est inséparable de la stratégie de réessai du firmware, de la gestion des courants de pointe, et de la patience de l'utilisateur pendant la configuration.
Un module solide peut toujours décevoir si l'antenne est mal placée, désaccordée par le boîtier, ou exposée à des retours de sol bruyants.
• Zones de sécurité pour les antennes et routage à impédance contrôlée.
• Effets de l'enveloppe et tests d'interaction avec les mains de l'utilisateur.
• Vérifications des émissions radiées et sondages de susceptibilité.
Lorsque la marge de liaison est mince, les réessais de firmware peuvent masquer le symptôme pendant un certain temps, mais le coût de la batterie s'accumule d'une manière qui est remarquée par les équipes opérationnelles bien avant que les ingénieurs ne le voient dans un laboratoire.
La conception de connectivité doit survivre à de véritables flux de travail plutôt qu'à des démos idéales.
• Provisionnement qui tolère des échecs partiels et des erreurs utilisateur courantes.
• Logique de recul et de réessai qui évite les spirales de décharge des batteries auto-infligées.
• Comportement d'itinérance plus gestion du cycle de vie SIM/eSIM pour les appareils cellulaires.
• OTA avec authentification, retour en arrière et planification consciente de la bande passante.
Les fonctions OTA fonctionnent moins comme une fonctionnalité brillante et plus comme un canal de maintenance à long terme ; lorsqu'elles sont traitées de manière décontractée, les appareils ont tendance à devenir coûteux à prendre en charge, même si le premier déploiement semble correct.
Gestion de l'énergie
La conception de l'alimentation garde le dispositif en vie, répétable et ennuyeux, dans le meilleur sens du terme. Elle couvre les régulateurs, la charge, l'évaluation de l'énergie, la commutation de charge et les choix de protection qui doivent gérer à la fois des événements de courant de crête et des attentes de sommeil profond.
La sélection des Buck/boost/LDO bénéficie de l'évaluation de l'efficacité sur l'ensemble de la plage de charge, et pas seulement un seul point de fonctionnement. Le courant de fuite en mode veille décide souvent si un produit répond aux attentes de la batterie.
Les radios peuvent créer des pics de courant brusques ; la capacité en vrac, le routage à faible impédance et les boucles de contrôle stables tendent à décider si le système reste opérationnel pendant les pics de transmission. De nombreuses réinitialisations mystérieuses se révèlent finalement être dues à des chutes transitoires plutôt qu'au firmware, ce qui peut être une leçon humiliante mais utile lors de l'intégration.
La durée de vie de la batterie est souvent remportée pendant le sommeil, où de petites fuites s'accumulent en pertes mesurables.
• Configuration de sommeil profond avec seulement les sources de réveil qui sont réellement utilisées.
• RTC ou minuteries basse consommation pour les réveils périodiques.
• Interruptions GPIO ou capteurs pour les réveils déclenchés par des événements.
• Alimentation en veille pour les capteurs et périphériques qui n'ont pas besoin de polarisation continue.
Mesurer l'état du sommeil dès le début sur du matériel réel, puis traiter les augmentations inattendues de microampères comme des bogues, tend à prévenir la lente érosion où de nombreux blocs « presque éteints » dégradent silencieusement le temps de fonctionnement.
Le choix de l'IC de charge dépend de la chimie, des limites thermiques, des contraintes réglementaires et de l'environnement prévu. La sélection du carburant doit refléter les besoins d'exactitude en fonction de la température, de la charge et du vieillissement. Pour les déploiements extérieurs ou non chauffés, le comportement à basse température devient souvent le facteur déterminant de la qualité perçue, donc des seuils de tension conservateurs et un rapport honnête de la capacité réduisent les plaintes d'arrêt brutal.
Les surintensités, les surtensions, la polarité inversée et le comportement ESD doivent être considérés comme des conditions de fonctionnement normales pour de nombreux déploiements. Les environnements industriels produisent couramment des événements de décharge de câble et des transitoires inductifs qui peuvent ressembler à de la « malchance » à moins que la conception ne les anticipe. Des pinces, des fusibles, des diodes TVS, un contrôle de montée en charge et des décisions d'isolation appropriées décident souvent si un appareil survit à son premier mois avec une réputation intacte.
Composants de stockage
Le stockage contient le firmware, la configuration, les certificats et les journaux. Le choix entre NOR/NAND flash, EEPROM, FRAM, eMMC ou microSD est souvent déterminé par l'endurance, la performance, le coût de la nomenclature et la difficulté qu'engendrerait une écriture corrompue sur le plan opérationnel.
Les appareils réels font face à des baisses de tension, des réinitialisations par watchdog et des écritures partielles.
• Sommes de contrôle ou CRC pour la configuration et les journaux.
• Équilibrage d'usure ou fréquence d'écriture limitée pour les médias basés sur la flash.
• Journalisation ou enregistrements en mode ajout seulement pour les données qui ne peuvent pas être écrites partiellement.
Un motif opérationnel fréquent est l'enregistrement en tampon circulaire avec des taux d'écriture limités, ce qui limite la consommation d'endurance silencieuse tout en laissant suffisamment de trace pour déboguer les problèmes sur le terrain.
Des emplacements de firmware A/B plus une logique de démarrage vérifiée et de retour en arrière fournissent un filet de sécurité pratique lors des mises à jour interrompues. Sans ces sauvegardes, une seule perte de courant pendant une mise à jour peut laisser des appareils à l'abandon sur le terrain. Les produits qui évoluent en douceur traitent généralement la récupérabilité au même niveau que l'expédition des fonctionnalités, car les coûts de support tendent à suivre la qualité de l'histoire de récupération.
Les certificats et les clés devraient être stockés en tenant compte de la résistance à la falsification et du contrôle d'accès, pas seulement quelque part en mémoire non volatile. Même avec un stockage sécurisé, des plans pour le changement de clé, la révocation et la réponse aux incidents réduisent l'exposition à long terme lorsqu'un appareil d'identification fuit ou qu'une flotte est partiellement compromise.
Composants d'interface
Les LED, les écrans, les boutons, les microphones, les caméras et les capteurs biométriques façonnent l'ergonomie, mais ils entraînent également une consommation d'énergie, un risque EMI, et des considérations de confidentialité. Une interface utilisateur qui semble cohérente sous stress reflète souvent davantage une conception électrique disciplinée qu'un poli de l'interface utilisateur.
Les boutons ont tendance à nécessiter un dé-bouncing et une protection ESD pour éviter les lectures sporadiques erronées.
Les microphones et les caméras ont tendance à nécessiter des rails propres et une mise à la terre soigneuse pour éviter des artefacts intermittents que les utilisateurs interprètent comme « peu fiables ».
• Séparation des chemins analogiques sensibles des chemins de commutation haute intensité et RF.
• Planification du chemin de retour pour limiter le couplage de bruit.
• Choix de blindage et de filtrage qui correspondent à l'enveloppe et à la stratégie de câblage.
Les pannes intermittentes de l'interface utilisateur sont fréquemment causées par un couplage provenant de radios ou de moteurs, et il peut être étonnamment satisfaisant de les corriger par une discipline de conception et de mise à la terre plutôt que par des solutions de contournement firmware sans fin.
Les appareils se comportent de manière plus prévisible lorsqu'ils ont une histoire hors ligne qui ne dépend pas de la disponibilité du réseau.
Un retour d'information local clair (états de LED non ambigus et signalisation d'erreur minimale et précise) tend à réduire la charge de support et évite la frustration de l'utilisateur qui vient d'un comportement de défaillance silencieuse.
Actionneurs
Les actionneurs convertissent l'intention de contrôle en mouvement, chaleur ou force, et ils nécessitent généralement des circuits d'interface au-delà d'une broche MCU directe. Parce que les actionneurs interagissent avec le monde physique, les modes de défaillance tendent à être visibles, coûteux et émotionnellement escalatoires pour les utilisateurs. Les moteurs, solénoïdes, vannes et relais ont couramment besoin d'étages MOSFET, de ponts en H ou de circuits intégrés pilotes dédiés dimensionnés pour de réelles intensités et transitoires.
• Diodes de roue libre ou snubbers pour les charges inductives.
• Détection de courant pour la détection de blocage et la réponse à la surcharge.
• Considérations de conception thermique pour des charges continues ou à haute durée de service.
L'expérience sur le terrain montre souvent que les problèmes liés aux actionneurs sont une source fréquente de défaillance, et une réduction conservatrice des performances ainsi qu'une détection des fautes tendent à améliorer le comportement de la flotte de manière à ce que les équipes de support s'en aperçoivent rapidement.
Un appareil doit rester sûr lorsque le firmware plante, que le cloud est inaccessible ou que des commandes arrivent en retard.
• Stratégie de watchdog et de réinitialisation alignée avec des sorties sûres.
• États de sortie par défaut sûrs définis par actionneur et par mode.
• Positions de sécurité mécanique où l'application l'exige.
Les conceptions les plus résilientes considèrent la perte de connectivité comme un mode de fonctionnement normal et définissent exactement ce que fait l'actionneur pendant cette période, de sorte que le comportement reste prévisible même lorsque tout le reste est imparfait.
Intégration au niveau système
Les améliorations à fort impact proviennent souvent de pratiques d'intégration qui forcent l'ensemble du système à dire la vérité tôt.
• Validation de l'intégrité de l'alimentation dans le cas de charges radio et actionneur les plus défavorables.
• Contrôle du bruit à travers la détection analogique, les régulateurs de commutation et les pilotes à haute courant.
• Flux de démarrage, mise à jour et récupération avec des états mesurables et une observabilité claire.
• Tests environnementaux (température, humidité, vibration) choisis pour correspondre aux conditions de déploiement réelles.
Lorsque ces activités sont traitées comme un travail d'ingénierie quotidien plutôt que comme une cérémonie de fin de phase, les choix de composants deviennent généralement moins dramatiques, et le comportement de l'appareil tend à rester cohérent du prototype au déploiement de masse.
Conclusion
Les systèmes IoT réussis reposent sur une boucle de données complète et fiable qui inclut la détection, le conditionnement du signal, le traitement, la communication, la sécurité et la gestion de l'énergie. Chaque étape affecte les performances générales, la durée de vie de la batterie, la précision et l'expérience utilisateur. En équilibrant le matériel, le logiciel, le réseau et les contraintes opérationnelles, les appareils IoT peuvent offrir une surveillance, un contrôle et une automatisation fiables dans une large gamme d'applications.
Questions Fréquemment Posées [FAQ]
1. Pourquoi de nombreux projets IoT échouent-ils à cause de la qualité de mesure plutôt que des problèmes de connectivité ?
La connectivité reçoit souvent le plus d'attention lors du développement parce que les tableaux de bord et les intégrations cloud sont très visibles. Cependant, des mesures inexactes causées par un placement inadéquat des capteurs, des vibrations, des effets de flux d'air, un couplage thermique, du bruit ou des erreurs d'installation peuvent compromettre l'ensemble du système. Si les données d'origine ne sont pas fiables, même les analyses les plus avancées, les plateformes cloud et les réseaux de communication ne peuvent pas produire de décisions fiables. Le succès à long terme de l'IoT commence généralement par des mesures stables plutôt que par des fonctionnalités de connectivité sophistiquées.
2. Pourquoi le montage des capteurs devrait-il être considéré comme faisant partie du système de détection lui-même ?
Les capteurs mesurent les conditions physiques par leur interaction avec l'environnement environnant. La force de montage, la conception du boîtier, le routage des câbles, le flux d'air, le transfert de vibration et le contact thermique peuvent tous modifier ce que perçoit le capteur. Un capteur parfaitement calibré peut encore produire des lectures trompeuses s'il est mal monté. Dans de nombreux déploiements, les erreurs liées à l'installation contribuent à plus d'incertitude de mesure que les spécifications du capteur elles-mêmes, faisant de l'intégration mécanique une partie critique de la performance globale de détection.
3. Pourquoi l'oversampling est-il souvent une menace cachée pour la durée de vie de la batterie dans les appareils IoT ?
Échantillonner des données plus fréquemment que nécessaire augmente la charge de traitement, l'utilisation de la mémoire et l'activité de communication. Étant donné que la transmission sans fil est souvent le plus grand consommateur d'énergie dans les produits IoT alimentés par batterie, la collecte de données excessives peut indirectement augmenter l'utilisation de la radio et réduire le temps d'exécution. Bien que des taux d'échantillonnage élevés puissent sembler améliorer la précision, ils créent souvent des ensembles de données plus volumineux sans offrir d'améliorations significatives dans la qualité des décisions. Des stratégies d'échantillonnage efficaces équilibrent les exigences de détection d'événements par rapport à la consommation d'énergie et aux besoins de reporting.
4. Pourquoi les appareils IoT réussis séparent-ils la logique de mesure de la logique de prise de décision ?
Les valeurs brutes des capteurs fluctuent naturellement en raison du bruit, de la variation de l'environnement et du comportement normal des processus. Si chaque mesure déclenche directement une action, les systèmes peuvent devenir instables et générer de fausses alarmes. En séparant la collecte de mesures de la logique de décision à l'aide d'hystérésis, de machines d'état, de filtres, de fenêtres de synchronisation et de règles de validation, les appareils peuvent rester réactifs tout en évitant des réactions inutiles à des fluctuations temporaires. Cette approche améliore la fiabilité et crée un comportement système plus prévisible dans des conditions réelles.
5. Pourquoi de nombreuses décisions critiques IoT sont-elles traitées localement au lieu d'être déléguées au cloud ?
Les systèmes cloud fournissent une analyse à long terme, une gestion de flotte et des informations prédictives précieuses, mais les délais et les pannes du réseau peuvent les rendre inadaptés aux fonctions de protection sensibles au temps. Des événements tels que des conditions de surintensité, une surchauffe, des blocages de moteur ou des arrêts de sécurité nécessitent souvent une action immédiate. Attendre une confirmation du cloud pourrait permettre à des dommages matériels ou à des conditions non sécurisées de se développer. Pour cette raison, les décisions critiques de protection et de contrôle sont généralement exécutées à la périphérie tandis que les plateformes cloud se concentrent sur la surveillance et l'optimisation.
Blog connexe
-
Combien de zéros dans un million, des milliards de milliards de billions?
![Combien de zéros dans un million, des milliards de milliards de billions?]()
2024/07/29
Des millions représentent 106, un chiffre facilement saisissable par rapport aux articles quotidiens ou aux salaires annuels. Milliards, équivalent ... -
Fiche technique MOSFET IRLZ44N, circuit, équivalent, épingle
![Fiche technique MOSFET IRLZ44N, circuit, équivalent, épingle]()
2024/08/28
L'IRLZ44N est un MOSFET de puissance à nailaux N largement utilisé.Renommé pour ses excellentes capacités de commutation, il est très adapté à ... -
Température de la batterie trop basse, la charge s'est arrêtée.Comment le réparer?
![Température de la batterie trop basse, la charge s'est arrêtée.Comment le réparer?]()
2024/10/6
Les problèmes de charge de batterie de téléphone portable sont courants mais peuvent être gérés efficacement.La température joue un rôle impor... -
BC547 Guide complet du transistor
![BC547 Guide complet du transistor]()
2024/07/4
Le transistor BC547 est couramment utilisé dans une variété d'applications électroniques, allant des amplificateurs de signal de base aux circuits... -
Guide complet du SCR (redresseur contrôlé en silicium)
![Guide complet du SCR (redresseur contrôlé en silicium)]()
2024/04/22
Les redresseurs contrôlés en silicium (SCR), ou thyristors, jouent un rôle central dans la technologie de l'électronique de puissance en raison de... -
LR621, SR621SW, 364, équivalents de batterie AG1 et remplacements
![LR621, SR621SW, 364, équivalents de batterie AG1 et remplacements]()
2024/07/15
Les batteries de bouton LR621 et SR621SW sont répandues dans des appareils électroniques compacts comme les montres, les petits jouets, les calculat... -
Un guide complet des multiplexeurs et leur rôle dans les systèmes numériques
![Un guide complet des multiplexeurs et leur rôle dans les systèmes numériques]()
2025/09/20
Les multiplexeurs sont des composants des systèmes numériques, conçus pour canaliser plusieurs signaux d'entrée dans une seule ligne de sortie en ... -
Fondamentaux des circuits d'amplificat
![Fondamentaux des circuits d'amplificat]()
2023/12/28
Dans le monde complexe de l'électronique, un voyage dans ses mystères nous conduit invariablement à un kaléidoscope de composants de circuit, à l... -
Comparaison des différences et applications des NMOS et PMO
![Comparaison des différences et applications des NMOS et PMO]()
2024/11/15
Comprendre les différences entre les transistors NMOS et PMOS est important pour concevoir des circuits efficaces.Les NMOS (N-Type Metal-Oxide-Semico... -
CR2450 vs CR2032 Comparaison: tout ce que vous devez savoir
![CR2450 vs CR2032 Comparaison: tout ce que vous devez savoir]()
2025/09/15
Les batteries de bouton comme CR2450 et CR2032 alimentent de nombreux appareils électroniques de tous les jours, des montres et télécommandes aux d...










Pièces chaudes
- HD64F36077GHV001
- LTC1702CGN
- AD80024JRSZ
- 74CBT3383PWR
- PIC18F67K22-I/PT
- TD62003F-TP1
- XC2V250-4FGG256C
- UPD9976F1-CAJ-E2-A
- MSP4450G-C13
- BZX84C16T-7-F
- CC1808JKNPOEBN150
- XC5204-5PQG160C
- MC33362DWG
- AM3354BZCZ100
- HD64F3067RF20V
- XPC8245LZU266B
- UCC27201DDA
- HX8806ALAG
- IRFP460
- WM8718SEDS
- TAJC106M035SNJ
- ATMEGA406-1AAU
- ADR4530ARZ-R7
- RT0805BRE0743KL
- LHL08TB100K
- AD8051ARZ-REEL
- WM8761GED/RV
- VND5T100LAJTR-E
- 08055U200GAT2A
- HD614042F
- UPD43256BGU-85L-E2
- CL05C121JB51PNC
- LMK325BJ476MM-T
- LTC1693-3CMS8TR
- BA8271F-E2
- 12103E684ZAT2A
- NTTFS4929NTAG
- T491X107K025ZT7280
- SR0402FR-7T10RL
- MAX418CSD
- VOS617A-1X
- XC95108-10PQG160C
- CQ1265RT
- GS88236BB-250
- MPC95BFA
- ISE2010Q
- M14D5121632AK1AG
- BCM53346A0KFSBLG
- 01609.0-01
- 1734-IE4S