- Français
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Programmation FPGA Xilinx et flux de conception Vivado expliqués
Catalogue

Exploration des tutoriels FPGA Xilinx
Travailler avec des FPGA peut sembler mentalement plus lourd que le logiciel au début, en partie parce que l'objectif n'est pas d'exécuter des instructions mais de décrire des structures matérielles qui fonctionnent en même temps. Vous finissez par penser à la concurrence, aux règles d'horloge, au comportement de réinitialisation et à savoir si les rapports de timing correspondent à ce que vous pensiez avoir construit. Lorsque les gens se frustrent tôt, ce n'est souvent pas en raison d'un manque d'efforts, mais parce que trop de parties mobiles changent entre les tentatives, et la cause de l'échec devient agaçante et glissante.
Une façon stable de progresser est de répéter le même flux de travail jusqu'à ce qu'il devienne suffisamment familier pour que les erreurs se démarquent. Gardez une carte Xilinx bien supportée sur votre bureau, commencez par un petit design HDL, simulez-le jusqu'à ce que les formes d'onde aient un sens, exécutez la synthèse et la mise en œuvre dans Vivado, programmez le dispositif, puis confirmez le comportement sur de vraies broches. Bien que ce processus puisse sembler répétitif, il aide à réduire l'incertitude quant à la cause d'un problème, qu'il soit dû au code de conception, aux contraintes ou à la configuration de la carte, rendant le débogage plus efficace.
Dans l'apprentissage quotidien, la partie raide de la courbe se regroupe généralement autour de quelques compétences qui se renforcent mutuellement : utiliser le flux de Vivado avec discipline, écrire du Verilog synthétisable qui correspond à ce que vous attendez, et déboguer les inévitables écarts entre la simulation et la carte physique avec une méthode en laquelle vous avez confiance. Si vous traitez chaque construction comme une expérience contrôlée, changez une variable, observez l'effet et notez ce que vous avez vu, vous remarquerez que vous passez moins de temps à deviner et plus de temps à former des instincts fiables.
Utilisez le flux de projet de Vivado d'une manière qui reste stable dans le temps
Vivado se comporte moins comme un simple bouton de compilation et plus comme un pipeline qui transforme RTL en une conception placée et routée qui doit vivre au sein des réalités électriques et temporisées de la carte. De nombreux débutants découvrent, parfois à leurs dépens, qu'une grande partie de la correction se trouve en dehors du HDL : les contraintes, les définitions d'horloge, les normes d'E/S et les paramètres des outils peuvent décider discrètement si le matériel se comporte comme la simulation le promet.
Un flux propre commence par garder la configuration du projet modeste et répétable, afin que vous puissiez dire quand vous avez réellement amélioré la conception par rapport à un changement accidentel d'environnement.
Choisissez une seule carte supportée et restez avec suffisamment longtemps pour développer une intuition que vous pouvez réutiliser. Les cartes avec une documentation solide et des conceptions de référence tendent à réduire l'anxiété de fond, car vous pouvez vérifier vos connexions de broches, vos horloges et vos hypothèses de puissance sans chercher des messages non officiels sur les forums.
Commencez par un module principal qui produit un résultat visible rapidement. Ce retour immédiat vous aide à valider que l'horloge fonctionne, que les broches sont correctement mappées et que les bitstreams sont générés de la manière dont vous pensez qu'ils le sont.
Exemples de comportements observables au niveau supérieur :
• Une LED clignotante
• Un écho UART
• Un compteur alimentant un GPIO
Une habitude pratique est de standardiser un petit modèle de niveau supérieur tôt. Par exemple, conservez une entrée d'horloge, une approche de réinitialisation que vous comprenez, et un petit paquet GPIO cohérent. Lorsque l'armature reste la même d'un projet à l'autre, vous pouvez concentrer votre attention sur la nouvelle logique au lieu de redériver les fondamentaux à chaque fois, ce qui peut sembler fastidieux et surprenant en termes d'erreurs potentielles.
Les contraintes font partie intégrante de la conception FPGA plutôt qu'une étape d'ajustement final. De nombreux problèmes matériels précoces se produisent même lorsque la conception RTL est correcte parce que des contraintes d'horloge manquent ou sont incorrectes, que les broches sont mal assignées, ou que les normes I/O ne correspondent pas aux exigences réelles du tableau.
Un flux de travail concret qui vous garde honnête est de définir les horloges dans XDC, de mapper les ports en utilisant le XDC maître du fournisseur comme référence, puis de vérifier les normes I/O par rapport au schéma du tableau. Ce processus peut sembler un peu bureaucratique au début, mais il tend à remplacer des soupçons vagues par des faits vérifiables.
La fermeture de temporisation n'est pas non plus réservée aux conceptions rapides. Même une logique qui semble lente sur papier peut avoir un mauvais comportement si l'outil déduit des relations d'horloge non intentionnelles ou si des signaux asynchrones sont traités de manière décontractée. S'habituer à lire des rapports de temporisation tôt peut réduire ce sentiment d'inconfort de « j'espère que c'est bon » lorsque les conceptions deviennent plus grandes.
Vivado vous dit constamment ce qu'il pense de votre conception ; la partie douloureuse est qu'il est facile de cliquer au-delà des avertissements puis de passer des heures à déboguer un problème déjà décrit sur la console. Avec le temps, les personnes qui avancent plus rapidement sont souvent celles qui établissent une habitude calme de vérifier les rapports après chaque exécution, même lorsqu'elles s'attendent à ce que tout soit en ordre.
Après chaque cycle de synthèse/implémentation, gardez ces catégories de rapport ensemble sur leur propre ligne de contrôle :
• Statut de temporisation et chemins critiques
• Utilisation des ressources (LUT/FF/BRAM/DSP) par rapport aux attentes
• Résultats d'inférence (pour les RAM, blocs DSP et autres structures prévues)
Lorsqu'un avertissement est présent depuis la première construction, il a tendance à continuer à apparaître dans les échecs les plus étranges plus tard. Une posture productive est de supposer que les avertissements méritent de l'attention jusqu'à ce que vous puissiez expliquer, en termes d'ingénierie simples, pourquoi ils sont bénins pour votre conception spécifique.
Écrivez du Verilog synthétisable qui se mappe proprement sur le matériel FPGA
Le travail HDL est plus proche de la conception de circuits que du développement d'applications, et ce changement peut être émotionnellement déroutant : vous pouvez écrire du Verilog valide qui simule magnifiquement tout en se synthétisant en quelque chose de plus lent, plus encombrant ou simplement différent de ce que vous imaginiez. L'objectif est de décrire des structures que le FPGA peut mettre en œuvre de manière prévisible : des bascules, de la logique LUT, de la BRAM et des blocs DSP, afin que le comportement et le timing correspondent à votre intention.
Lorsque le mappage est prévisible, le débogage ressemble moins à une dispute avec l'outil et plus à un perfectionnement de la conception.
Une base confortable pour de nombreux débutants est un seul domaine d'horloge avec une logique synchrone directe. Utilisez des blocs toujours horlogés pour l'état séquentiel et des attributions continues (ou des blocs combinatoires correctement écrits) pour les chemins combinatoires. Créer une logique « semblable à une horloge » dans le tissu peut fonctionner dans des cas de niche, mais cela tend à inviter à des risques liés aux domaines d'horloge à moins que vous ne compreniez déjà le gating d'horloge, le routage et les implications de timing.
Le comportement de réinitialisation est un autre domaine où de petits choix peuvent créer des résultats de tableau étonnamment inconsistants. Les réinitialisations asynchrones peuvent être utiles, mais elles peuvent également produire des risques de désactivation ou une sensibilité aux différences de mise sous tension au niveau du tableau. De nombreuses conceptions FPGA utilisent des réinitialisations entièrement synchrones ou une assertion asynchrone avec une libération synchrone parce que ces approches aident à réduire le comportement de démarrage incohérent lors des tests de mise en service.
La logique FPGA s'appuie naturellement sur des pipelines et des structures parallèles. Une déception courante chez les débutants est d'attendre une exécution étape par étape similaire à celle du logiciel, puis de se sentir confus lorsque tout se passe en même temps. Une approche plus utile est de décider ce qui vous importe pour un bloc donné puis de concevoir explicitement pour ce résultat.
Une lentille de conception en une seule ligne pour la performance et le mappage :
• Débit (éléments par horloge)
• Latence (cycles de l'entrée à la sortie)
• Préférence de mappage des ressources (LUT contre BRAM contre DSP)
Par exemple, une addition-multiplication peut inférer proprement des tranches DSP, mais de légers changements de style de codage peuvent pousser l'outil vers une arithmétique basée sur LUT. Lorsque l'utilisation vous surprend, il vaut souvent la peine de faire une pause et de poser une question légèrement inconfortable : avez-vous réellement décrit la structure matérielle que vous aviez l'intention, ou avez-vous décrit quelque chose de fonctionnellement équivalent qui coûte plus de ressources ?
La simulation acceptera joyeusement des constructions que le matériel réel ne peut pas mettre en œuvre de la façon dont vous pourriez l'imaginer. Garder votre frontière synthétisable claire réduit la fausse confiance et rend les résultats de simulation plus portables vers le tableau.
Modèles communs à garder regroupés sur une seule ligne comme un rappel rapide :
• Évitez les retards (#) dans la logique synthétisable
• Ne comptez pas sur l'initialisation à moins que vous ayez confirmé le comportement de l'appareil/de l'outil
• Surveillez les verrous involontaires dus à des affectations combinatoires incomplètes
• Utilisez des synchroniseurs appropriés pour les traversées de domaine d'horloge
Une habitude qui tend à porter ses fruits est d'écrire de petits bancs d'essai auto-vérifiants qui valident les hypothèses que vous êtes émotionnellement tenté de négliger : comportement de réinitialisation, réinitialisation de compteur, protocoles de handshake et conditions limites. Lorsque les projets grandissent, ces tests deviennent moins un travail supplémentaire et plus la chose qui vous empêche de tout remettre en question.
Déboguer systématiquement avec simulation et visibilité sur puce (ILA)
Même une excellente simulation ne garantit pas un comportement correct du tableau. Le matériel réel apporte du jitter d'horloge, des retards d'E/S, des états initiaux inconnus et des entrées asynchrones qui ne s'alignent pas poliment à votre bord d'horloge. Les débogueurs les plus rapides ne sont généralement pas ceux qui effectuent des éditions aléatoires, ce sont ceux qui réduisent le problème par des observations structurées et peuvent expliquer quels éléments de preuve ont changé leur avis.
Un banc d'essai solide vérifie le comportement sur de nombreux cycles et n'évite pas les scénarios inconfortables. Si vous modélisez un stimulus réaliste, la simulation devient un endroit où vous construisez la confiance, pas seulement un endroit où vous regardez un signal basculer et espérez qu'il signifie quelque chose.
Stimuli réalistes qui tendent à exposer une logique fragile :
• Rebond de bouton
• Erreurs de cadrage UART
• Contre-pression dans les interfaces de streaming
• Séquences de réinitialisation avec un temps d'attente délicat
Il est également utile de séparer les bogues en deux catégories afin de ne pas poursuivre le mauvais type de correction :
• Bogues fonctionnels : la logique RTL est incorrecte
• Bogues d'intégration : la RTL est correcte, mais les horloges/réinitialisations/contraintes/assumptions sur l'E/S sont erronées
La simulation est excellente pour déceler les bogues fonctionnels ; les tests sur le tableau ont tendance à révéler des bogues d'intégration que vous ne vouliez pas croire possibles.
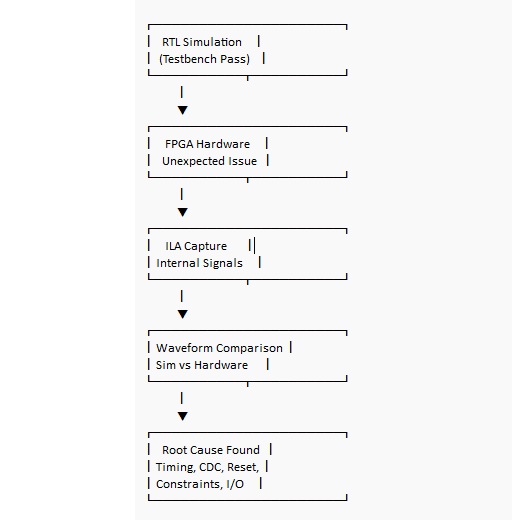
Quand le comportement du matériel désaccorde avec votre banc d'essai, l'analyseur logique intégré (ILA) est souvent le moyen le plus direct de remplacer la spéculation par un trace que vous pouvez étudier. Projetez des signaux qui représentent des décisions et des limites à l'intérieur du design, puis capturez le moment où les choses divergent et comparez-le à la forme d'onde de simulation attendue.
Signaux qui tendent à être des sondes de grande valeur :
• Codages d'état FSM
• Handshakes valides/prêts
• Indicateurs FIFO plein/vide
• Sorties des synchroniseurs de réinitialisation
Un flux de travail pratique consiste à commencer par moins de sondes et une fenêtre de capture plus large. À mesure que vous apprenez où se trouve l'échec, vous pouvez resserrer le déclencheur et ajouter des détails. Trop d'instrumentation peut réduire la marge de timing et compliquer les constructions, il est donc souvent plus sain de considérer l'insertion ILA comme une étape de mesure ciblée plutôt que comme quelque chose que vous gardez juste au cas où.
Certaines des échecs les plus éducatifs se produisent lorsque la simulation semble sans défaut et que le tableau est instable. Ce décalage peut sembler décourageant, mais c'est aussi là que l'intuition FPGA devient plus aigüe, car la solution se trouve généralement dans l'horlogage, les contraintes ou l'hygiène des signaux plutôt que dans l'algorithme.
Causes communes de divergence entre simulation/plateforme :
• Contraintes d'horloge manquantes ou incorrectes
• Métastabilité due à des entrées non synchronisées
• Variation du temps d'activation de la réinitialisation à travers la puce
• Problèmes de CDC entre plusieurs domaines d'horloge
• Différences dans les conditions initiales
Une perspective qui tend à accélérer l'apprentissage est de considérer le timing et l'observabilité comme des propriétés que vous intégrez délibérément dans le design. Lorsque vos petits projets définissent explicitement les horloges, contraignent les E/S, synchronisent les traversées et exposent les signaux internes pour mesure, vous passez moins de temps à espérer que cela fonctionne et plus de temps à faire des améliorations contrôlées et explicables. Cet état d'esprit s'adapte naturellement d'une LED clignotante à de plus grands pipelines, interfaces et systèmes embarqués sur le même dispositif.
Xilinx (AMD) vs. Altera (Intel) FPG
Xilinx (AMD) et Intel (Altera) expédient tous deux des familles de FPGA qui semblent comparables sur papier, et il est facile de se sentir confiant après un rapide coup d'œil à la fiche technique. L'humeur a tendance à changer plus tard, lorsque les réalités d'ingénierie au quotidien commencent à décider du rythme : comportement de l'outil sur votre appareil et votre grade de vitesse exact, si l'IP que vous supposiez pouvoir utiliser est en fait licenciable dans votre organisation, si un design de référence aligne réellement avec vos horloges et réinitialisations, et si la fermeture de timing reste stable une fois que le design devient de qualité production.
Un processus de sélection est plus efficace lorsque vous traitez le FPGA comme un système de livraison, appareil + outils + IP + tableaux + documentation + maintenabilité à long terme, car c'est à cet endroit que les équipes prennent soit de l'élan (et du sommeil), soit accumulent tranquillement de l'anxiété liée au calendrier.
| Fonctionnalité |
Xilinx (AMD) |
Intel (Altera) |
| Position sur le marché |
Historiquement le leader du marché, connu pour un large portefeuille de produits et d'être le premier à lancer de nouvelles technologies. |
Concurrent fort, particulièrement puissant dans les applications de centre de données et de mise en réseau, tirant parti de l'expertise de fabrication d'Intel. |
| Architecture de base |
La logique est principalement basée sur des tables de correspondance à 6 entrées (LUT), offrant une grande granularité et flexibilité. |
Utilise des modules de logique adaptatifs (ALM), qui sont plus complexes et peuvent être configurés comme des LUT plus grandes, améliorant potentiellement la densité logique pour certains designs. |
| Suite logicielle |
Vivado Design Suite et Vitis Unified Software Platform. Souvent loué pour son interface conviviale pour les développeurs expérimentés. |
Quartus Prime Design Suite. Certains utilisateurs trouvent son interface graphique plus intuitive pour les débutants, et elle est connue pour des temps de compilation plus rapides dans certains scénarios. |
| Familles haut de gamme |
Versal ACAPs (Plateformes d'accélération de calcul adaptatif) combinant des moteurs scalaires, adaptables et intelligents. |
FPGAs Agilex, connus pour leur haute performance et leur efficacité énergétique, avec certains benchmarks montrant un avantage en performance par watt. |
| Concentration sur l'écosystème |
Fort accent sur l'intégration du processeur et du FPGA, comme le montre la famille Zynq. Populaire pour le développement d'applications. |
Bien adapté aux conceptions System-on-Chip et aux applications industrielles, avec un solide portefeuille IP pour le réseau et les RF. |
Définir la sélection en utilisant des contraintes vérifiables, pas des attentes de marque
Commencer par des exigences que vous pouvez tester tôt, pas par des impressions de projets antérieurs. L'objectif est de réduire les « surprises à la semaine 10 », qui est là où la frustration et le retravail ont tendance à s'accumuler.
Liste de contrôle des contraintes :
• Ressources logiques : LUT/ALM, registres, disponibilité de routage et plafond d'utilisation attendu
• Ressources DSP : nombre de blocs, modes de précision, pré-adders, options de cascade/topologie et comportement de mappage pour vos noyaux mathématiques
• Mémoire sur puce : BRAM/URAM (ou équivalents M20K), capacité totale, modes de port, bande passante par horloge et modèles de contention
• I/O haute vitesse : classe SERDES, nombre de voies, taux de ligne maximum, options d'horloge de référence et support de protocole lié à votre cas d'utilisation
• Mémoire externe : variantes DDR3/DDR4/LPDDR, maturité du contrôleur, comportement de calibration et hypothèses de marge SI au niveau de la carte
• Latence et déterminisme : cible de bout en bout, budget par étape, tolérance aux variations et stratégie CDC (y compris comment les réinitialisations traversent les domaines)
• Envelope de puissance/thermique : estimations de commutation dans le pire des cas, modes de puissance du transceiver, hypothèses de dissipation thermique et plage ambiante
Les projets FPGA réels montrent souvent que s'intégrer dans le dispositif ne garantit pas un fonctionnement fiable à haute vitesse. Les conceptions qui semblent acceptables à 70–80% d'utilisation peuvent devenir instables après l'ajout de logique de débogage, de protection CDC, de FIFOs, de gestion des erreurs, et de la marge de synchronisation nécessaire pour un fonctionnement pratique.
Si votre équipe a déjà perdu une semaine à cause de la congestion de routage, l'attrait d'augmenter d'une taille de dispositif est facile à comprendre. Le compromis de coût n'est généralement pas linéaire : une pièce légèrement plus grande peut acheter un chronométrage plus calme, moins d'itérations d'outils et moins de reconstructions tard dans la nuit.
Traitez le flux d'outils comme une exigence que vous ne pouvez pas expédier
Le flux d'outils tend à être le séparateur caché entre le plan qui semble solide et le plan qui continue de glisser. Les gens sous-estiment souvent combien de ressources émotionnelles sont consommées par des itérations lentes ou imprévisibles, surtout lorsqu'une construction prend des heures et que le mode de défaillance est vague.
Liste de contrôle pour l'évaluation du flux d'outils :
• Vitesse d'itération : synthèse + placement/routage + temps de bitstream sur votre matériel CI, pas sur une machine de démonstration du fournisseur
• Comportement de clôture temporelle : tendances QoR, stabilité à travers les semences et sensibilité aux petits changements de contrainte
• Contraintes et observabilité : clarté SDC/XDC, précision de la modélisation d'horloge, gestion des chemins faux/multicycle et à quel point les violations sont débogables
• Instrumentation de débogage : flux d'insertion d'analyseur logique, flexibilité de sonde, profondeur de déclenchement et à quelle fréquence vous devez recompiler pour observer des signaux
• Adéquation environnementale : versions d'OS prises en charge, constructions sans interface, friction de licence et à quel point cela correspond au flux de travail de votre équipe
• Amabilité CI/VCS : reproductibilité, sorties déterministes (autant que les outils le permettent), scriptabilité et douleur de mise à niveau
Avant de vous engager, exécutez un essai de clôture temporelle sur quelque chose de représentatif (pas un jouet). Incluez vos vraies horloges, au moins une interface de mémoire externe, et au moins un bloc I/O haute vitesse. Suivez :
• Temps de compilation réel par itération
• Stabilité de slack à travers quelques semences
• À quelle vitesse un ingénieur peut diagnostiquer les trois premiers problèmes de synchronisation sans connaissance tribale
Cet expériment tend à produire une sorte de clarté que les listes de vérification des fonctionnalités ne fournissent pas. Cela révèle également si votre équipe se sentira stable ou constamment tendue pendant la phase d'intégration.
Disponibilité de l'IP et licences : là où les plannings deviennent généralement serrés
Même lorsque les ressources FPGA brutes semblent similaires, les plannings dépendent souvent des réalités de l'IP. C'est ici que les équipes peuvent se sentir prises au dépourvu : le cœur existe, mais le modèle de licence, l'effort d'intégration ou la qualité de la documentation le transforme en un lent effort.
Liste de vérification de l'IP et des licences :
• Piles de protocoles : PCIe, Ethernet MAC/PCS, JESD204, contrôleurs DDR, et toutes les interfaces de niche sur lesquelles vous comptez
• Conditions de licence : verrouillées sur un nœud vs flottantes, modules complémentaires, implications pour les serveurs de construction/CI, et toutes contraintes d'exécution ou de déploiement
• Designs de référence : comptes de voies, plan d'horloge, séquence de réinitialisation, architecture DMA, et s'il correspond aux limites de votre système
• Horizon de support : attentes de maintenance à long terme, cadence de patchs, et comment les problèmes sont triés
Un point subtil que les équipes apprennent à leurs dépens : l'IP disponible n'est pas la même chose que l'IP à insérer. Les démonstrations en laboratoire peuvent cacher le travail d'intégration nécessaire pour atteindre vos cibles de latence, de mise en mémoire tampon et d'horloge. Prévoir du temps pour la validation et privilégier l'IP avec une documentation directe et des exemples avérés réduit souvent le niveau de stress par la suite, même si l'évaluation initiale semble plus lente.
Écosystème des cartes, risque de mise en service et confort des plateformes fiables
Le choix du FPGA est lié à la réalité des cartes. Pendant la mise en service, le temps disparaît souvent dans l'incertitude de la plateforme plutôt que dans le RTL : une contrainte d'horloge manquée, une dépendance de réinitialisation qui n était pas évidente, ou un canal de transcepteur qui est marginal seulement à certaines températures.
Liste de vérification des cartes et des plateformes
• Cartes d'évaluation et plateformes de référence : disponibilité, stabilité de révision, et si le design est largement utilisé sur le terrain
• Directives pour l'alimentation : cibles PDN, approche de découplage, attentes de séquençage des rails, et hypothèses de tolérance des empilements
• Références de mise en page haute vitesse : directives de routage des transceivers, notes de conformité, et empilements éprouvés
• Accès au débogage : stabilité JTAG, modes de démarrage/configuration, support de flash de configuration, et visibilité sur les rails/horloges
• Réactivité du support : canaux des fournisseurs, rapport signal-bruit de la communauté, et délai de réponse pour les problèmes d'outils/IP
Utiliser une plateforme largement adoptée avec des designs de référence éprouvés peut rendre la mise en service du système plus structurée et prévisible. Cette approche aide à faire passer le dépannage d'une incertitude large à une vérification mesurable étape par étape, améliorant l'efficacité du développement.
Fermeture de timing
La fermeture de timing est là où les différences entre fournisseurs deviennent tangibles, surtout lorsque l'utilisation augmente et que plusieurs domaines d'horloge interagissent. À ce stade, les progrès du design peuvent soit rester stables et prévisibles, soit devenir difficiles lorsque de petits changements créent de grandes variations de timing.
• Échelle de congestion : comment la pression de routage augmente à mesure que l'utilisation monte, et où elle commence à monter en flèche
• Prévisibilité de Fmax : à quelle fréquence des contraintes modérées vous rapprochent, par rapport à nécessiter un réglage manuel important
• Qualité des rapports : si les rapports de timing indiquent des corrections exploitables, et non simplement de longues listes de violations
• Robustesse : comportement à travers la variation PVT et à travers les graines d'implémentation
Il est généralement plus sûr de supposer que les efforts de fermeture augmentent de manière non linéaire avec la densité. Au-delà d'un certain seuil, un petit ajustement RTL peut faire basculer le slack de sain à fragile. Le slack architectural, le pipelining, la planification de sol sélective et le choix d'un dispositif avec de la marge améliorent souvent les réglages héroïques de contrainte que personne n'aime maintenir.
Comparez la pièce exacte
Les spécifications varient selon les générations et à l'intérieur d'une même famille. Deux pièces avec des noms similaires peuvent se comporter différemment au point de perturber un plan, en particulier une fois que l'emballage, le grade de vitesse et la maturité des outils entrent en jeu.
• Grade de vitesse : Fmax réalisable, comportement de la marge des transceivers, et différences dans les modèles de timing
• Emballage : nombre d'E/S, placement des banques, impact SI, comportement thermique, et contraintes d'assemblage
• Limites des fonctionnalités SKU : blocs désactivés, capacités de transceivers réduites, ratios de mémoire, ou limitations de protocole sur certaines variantes
• Maturité des outils : niveau de support du dispositif, cadence de sortie, et si votre équipe peut se standardiser sur une version d'outil stable
Méthode de comparaison pratique :
• Modèles de timing des fournisseurs mappés à vos horloges et interfaces réelles
• Estimation de la puissance utilisant des taux de changement, des cycles de travail et des réglages de transceivers réalistes
• Contraintes de pinout/bank alignées à vos exigences de carte et carte de connecteurs
• Versions d'outils avec lesquelles votre organisation peut vivre pendant la durée de vie du produit (y compris CI)
Un cadre décisionnel qui a tendance à tenir bon lorsque les choses deviennent stressantes
Lorsque la pression du calendrier augmente, un cadre basé sur des mesures aide à éviter les pivots motivés par le regret. Cela aide également l'équipe à se sentir plus stable, car les décisions ont une trace écrite liée aux résultats observés plutôt qu'à l'optimisme.
Ordre de sélection équilibré :
1) Verrouiller les exigences mesurables : ressources, I/O, mémoire, latence et budget énergétique/thermique.
2) Prototyper le sous-système le plus difficile sur chaque candidat : comportement temporel + flux de débogage + boucle de construction/CI.
3) Évaluer la maturité de la PI et la licence par rapport à votre plan d'intégration, et non pas aux résumés marketing.
4) Choisir l'option avec une marge de manœuvre et la boucle d'itération la plus prévisible, plutôt que celle qui à peine dépasse les minimums.
L'idée principale est que le meilleur FPGA est rarement celui avec les chiffres les plus accrocheurs. Les équipes avancent généralement plus rapidement, et avec moins de doutes, lorsque la plateforme soutient une convergence stable, des constructions répétables et des solutions durables tout au long de la vie du produit.
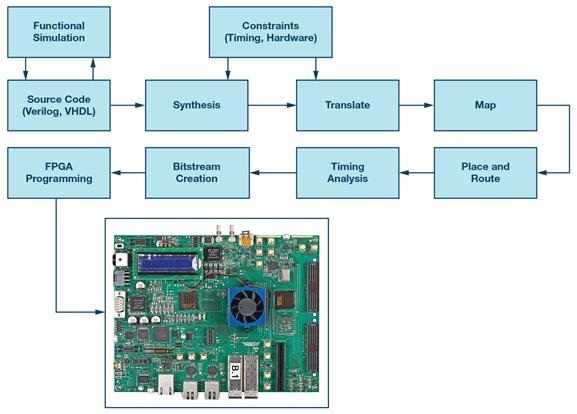
L'outil fondamental

Le rôle de Vivado dans le workflow FPGA
Vivado a tendance à devenir le centre opérationnel d'un projet FPGA Xilinx, non pas parce qu'il est glamour, mais parce que c'est là où chaque hypothèse est finalement testée par rapport à la réalité des outils. Il ingère le HDL et les contraintes, produit une liste de portes, exécute le placement et le routage tout en équilibrant les règles de timing et de conception physique, puis génère un flux binaire qui programme le dispositif.
Une façon pratique de comprendre Vivado est de le considérer comme deux systèmes connectés : un système de conversion RTL en liste de portes et un optimiseur d'implémentation physique. Cela explique pourquoi RTL logiquement correct peut encore produire des résultats instables ou incohérents lorsque les contraintes sont incomplètes, que les définitions d'horloge sont inexactes, ou que la structure de conception crée des difficultés de routage et de timing.
La plupart des projets suivent un pipeline familier, même lorsque les détails diffèrent selon la famille de dispositifs et le style de flux.
• Synthèse : traduit le RTL en une représentation au niveau des portes et infère des structures spécifiques au dispositif.
• Implémentation : effectue le placement, le routage et l'optimisation sous contrainte physique.
• Génération de flux binaire : émet l'image de configuration et vérifie le résultat implémenté par rapport aux contraintes et aux règles de l'outil.
Un calendrier a tendance à devenir tendu non pas lorsque qu’un flux binaire est produit une fois, mais lorsque l'équipe a besoin que le flux binaire se comporte comme une sortie fiable : résultats similaires lors des reconstructions, marges temporelles qui survivent à la vitesse cible, et stabilité lorsque de petites modifications RTL sont apportées pour des corrections fonctionnelles. C'est là que ce qui a été construit hier cesse d'être réconfortant.
Les équipes qui avancent plus rapidement avec le temps ont généralement cessé de considérer les rapports comme de la paperasse et commencent à les traiter comme des preuves d'ingénierie. Lorsque les artefacts de construction sont collectés de manière cohérente, les discussions sur la conception deviennent moins émotionnelles et plus concrètes, ce qui est un soulagement lorsque les délais approchent.
• Rapports de synthèse/implémentation : utilisation, primitives inférées, avertissements et résumés structurels.
• Sorties temporelles : WNS/TNS, points de terminaison échouant, chemins détaillés et résumés d'interaction d'horloge.
• Contraintes XDC : horloges, règles I/O, exceptions et affectations de broches physiques.
• Points de contrôle implémentés (DCP) : instantanés reproductibles qui soutiennent des itérations rapides et des expériences contrôlées.
Un schéma qui se manifeste dans le travail réel est qu'un ensemble de rapports soigné et cohérent en interne prédit souvent des progrès plus fluides qu'une seule bannière verte "PASS". La bannière peut cacher la fragilité ; les rapports, en général, ne le font pas.
Installation et configuration de l'environnement
Une configuration qui lance simplement l'interface graphique est facile à célébrer et facile à regretter plus tard. Les configurations auxquelles les équipes font confiance sont ennuyeuses dans le bon sens : elles se comportent de la même manière sous l'automatisation, elles sont cohérentes sur les machines et elles ne vous surprennent pas après une mise à jour d'outil.
Choisissez l'édition Vivado ML qui correspond à vos cibles de dispositifs, puis activez uniquement les familles de dispositifs que vous prévoyez réellement de construire. Cela réduit l'utilisation du disque et le temps d'indexation, et cela réduit également les chances d'erreurs de configuration accidentelles entre les familles qui peuvent faire perdre un après-midi.
Dans les équipes de développement multi-cartes, maintenir une liste définie des dispositifs supportés pour chaque projet aide à maintenir le développement plus contrôlé et cohérent que de se fier à quels que soient les outils ou les pièces installés.
Les sorties de Vivado peuvent varier d'une version à l'autre car les algorithmes de placement, de routage et de timing évoluent et les bugs sont corrigés (ou remplacés par d'autres bugs). De nombreuses équipes obtiennent des constructions plus calmes en fixant une version d'outil par branche de version et en mettant à jour par étapes planifiées plutôt qu'en dérivant continuellement.
Lorsqu'ils essaient une version plus récente, les équipes comparent souvent les signaux pratiques de la santé de l'outil avant de l'adopter comme nouvelle référence : marges de timing, changements d'utilisation, deltas d'avertissement et tout nouveau message de couverture de contrainte. Le temps passé à faire cette comparaison est généralement plus facile que de discuter tard dans le cycle de savoir si le timing s'est soudainement détérioré sans raison.
Pour les constructions en ligne de commande, les systèmes CI et les serveurs de construction partagés, l'environnement de développement doit se comporter de manière cohérente sur tous les systèmes au lieu de dépendre des configurations de machines individuelles.
• Scripts de paramètres : sourcez les bons paramètres d'outil afin que les chemins, bibliothèques et dépendances d'exécution se résolvent de manière cohérente.
• Flux pilotés par Tcl : privilégiez les constructions scriptées pour des exécutions répétables, des rapports uniformes et une intégration CI.
• Discipline de l'interface de construction : gardez les entrées et sorties stables afin que les changements soient intentionnels et examinables.
Un flux de travail de développement courant consiste d'abord à terminer une construction GUI stable pour vérifier la conception, puis à passer à un flux basé sur Tcl afin que le processus de construction ne dépende plus des paramètres GUI, des données mises en cache ou des différences entre les machines de développement.
Les rapports que vous voudrez lire comme des diagnostics
La plupart des moments de défaillance de la conception ne sont pas mystérieux longtemps si les rapports sont lus comme une histoire de ce que l'outil croyait. Les avertissements, la couverture de contrainte et les chemins de timing tendent à documenter le mode de défaillance en pleine vue, même si ce n'est pas toujours dans le meilleur ordre.
Les équipes s'améliorent plus rapidement lorsqu'elles traitent les sorties de Vivado comme une boucle de feedback quotidienne plutôt que comme quelque chose que vous ouvrez uniquement lorsque la construction échoue.
Ces rapports sont souvent le premier endroit où la dérive d'intention devient visible, et cela peut être paradoxalement rassurant : au moins, le problème est concret.
• Utilisation des ressources : LUT, FF, BRAM, DSP, URAM par rapport aux limites et à l'espace disponible de l'appareil.
• Vérifications d'inférence : styles de RAM inattendus, inférence DSP manquante, mappage primitif surprenant.
• Signaux d'alerte structurels : réseaux à grande influence, multiplexage large, longues chaînes combinatoires.
• Avertissements : inférence de verrou, gestion incomplète de la sensibilité, logique non connectée ou tronquée.
L'inférence de verrou et les chemins combinatoires longs non intentionnels apparaissent fréquemment dans la pratique. L'outil les mettra en œuvre sans se plaindre, et cela peut sembler trompeur lorsque le timing refuse plus tard de coopérer de manière à sembler aléatoire jusqu'à ce que les rapports de chemin soient lus.
La fermeture du timing devient moins stressante lorsque l'équipe sait ce que l'outil optimise et pourquoi il choisit certains compromis.
• Signaux de détente : WNS comme la pire violation unique ; TNS comme la répartition globale des violations.
• Décomposition des chemins : où le délai s'accumule (profondeur logique, routage, horloge ou suppositions de contrainte).
• Modélisation des horloges : si les chemins sont analysés comme prévu, ignorés ou groupés incorrectement.
Une leçon nuancée que les équipes expérimentées intègrent est que la douleur du timing est souvent d'abord un problème de modélisation de contrainte et ensuite un problème RTL. Lorsque le modèle d'horloge est incorrect, il peut passer des jours à optimiser les mauvais points de terminaison et avoir l'impression que l'outil n'écoute pas.
Les lacunes de contrainte sont des récidivistes, en partie parce qu'elles ne paraissent pas toujours dramatiques jusqu'à ce que le projet soit bien avancé.
• Lacunes de définition d'horloge : horloges principales manquantes ou incorrectes.
• Lacunes d'horloge générée : horloges divisées/multipliées/acheminées non déclarées, forçant l'outil à deviner.
• Lacunes de définition I/O : contraintes I/O manquantes qui conduisent à des suppositions optimistes et à de surprises au niveau du circuit imprimé.
• Mauvais usage des exceptions : exceptions manquantes ou exceptions trop larges pour être fiables.
Une habitude pragmatique est de traiter le XDC comme une spécification vivante plutôt que comme un fichier de correctif. Lorsque des exceptions sont introduites, les équipes qui dorment mieux ont tendance à les garder étroites, expliquées et liées à une véritable relation de timing plutôt que de les utiliser pour apaiser des violations qui méritent un examen.
Stratégie de contrainte XDC
Le fichier XDC est l'endroit où l'intention de conception est forcée de devenir explicite. Lorsqu'il est légèrement incorrect, le comportement de timing résultant peut sembler chaotique même si l'outil est parfaitement déterministe.
Définissez les horloges explicitement, puis vérifiez que l'outil les a propagées comme vous l'attendiez. Les problèmes de modèle d'horloge sont souvent plus faciles à corriger que les problèmes de timing architecturaux plus profonds, ce qui les rend plus simples à résoudre lors de l'analyse du timing et du débogage.
• Horloges principales : définies à partir des broches ou des sorties MMCM/PLL.
• Horloges générées : définies pour les domaines divisés, multipliés ou transférés.
• Relations asynchrones : déclarées via des groupes d'horloges ou des relations explicites.
Sur de vraies cartes, une horloge générée manquée peut produire une image de timing trompeuse qui brûle des jours, surtout lorsque l'outil optimise vers des points de terminaison qui n'étaient jamais destinés à être analysés ensemble.
Les contraintes d'E/S façonnent les hypothèses électriques et temporelles utilisées par l'outil, et cela peut déterminer discrètement si le succès en laboratoire se transforme en « succès système ».
• Normes électriques : normes et tensions d'E/S alignées avec la conception de la carte.
• Discipline de pinning : verrouiller les emplacements des broches une fois le mappage stabilisé pour éviter le churn.
• Timing des interfaces : délais d'entrée/sortie qui reflètent le dispositif externe, et non les valeurs par défaut de l'outil.
Une déception familière en fin de processus est : cela a respecté le timing lors de la construction, mais l'interface échoue sous un trafic réel. Ce résultat remonte souvent aux hypothèses d'E/S par défaut qui n'ont jamais été mises à jour pour correspondre au budget temporel de la carte et du dispositif externe.
Les exceptions peuvent clarifier l'intention, et elles peuvent aussi créer une illusion fragile de progrès si elles survivent à leur justification initiale.
• Chemins faux : utilisés uniquement lorsque le chemin ne fait vraiment pas partie du timing fonctionnel.
• Chemins multicyle : utilisés uniquement lorsque la relation de capture s'étend vraiment sur plusieurs cycles et est documentée.
• Hygiène des exceptions : garder l'ensemble petit, le réviser après des changements majeurs de RTL/pipeline, et retirer les entrées obsolètes.
Certains des bogues de timing les plus coûteux proviennent d'exceptions qui étaient exactes autrefois, devenant ensuite silencieusement inexactes après un changement de pipeline. L'outil se conformera sans se plaindre, ce qui rend ce mode de défaillance si désagréable.
Modèles de défaillance typiques et comment les résoudre efficacement
Certains problèmes se répètent à travers les projets, peu importe si l'application concerne le réseau, la vision, le contrôle ou l'accélération. Reconnaître le schéma tôt tend à réduire la charge émotionnelle du débogage, car l'équipe peut passer de « pourquoi cela se produit-il » à « quel manuel d'opérations s'applique ».
Cette situation donne souvent l'impression que l'outil est têtu, mais les causes profondes sont généralement traçables.
• Profondeur combinatoire : longs chemins causés par un pipeline manquant ou insuffisant.
• Pression de fanout : réseaux de contrôle à fort fanout qui bénéficient de la réplication, du buffering ou de la restructuration.
• Modélisation des contraintes : définitions de l'horloge ou relations qui caractérisent mal ce qui doit être analysé.
Une séquence qui tend à bien fonctionner est : valider le modèle temporel (horloges et relations), se concentrer d'abord sur les points d'extrémité les plus défaillants, puis s'élargir aux changements architecturaux uniquement si les preuves de chemin le soutiennent.
C'est l'une des expériences les plus démoralisantes dans le travail FPGA, principalement parce que cela donne l'impression que la réalité est injuste. En général, c'est juste que la simulation n'a pas stressé les mêmes modes de défaillance.
• Comportement CDC/réinitialisation : séquençage de réinitialisation et passages de domaine d'horloge que la simulation n'exerce que rarement de manière réaliste.
• Hypothèses d'E/S : E/S non contraintes ou mal contraintes qui produisent des interfaces réelles marginales.
• Comportement d'initialisation : dépendance à des valeurs initiales qui ne s'alignent pas proprement sur le comportement de mise sous tension du dispositif.
Les équipes qui deviennent plus stables intègrent la stratégie CDC et de réinitialisation tôt dans la discussion de conception, les considérant comme faisant partie de l'architecture de conception plutôt que comme une phase de nettoyage après que la « logique réelle » soit terminée.
Ce problème est courant car le placement et le routage réagissent fortement aux changements de structure de netlist, même lorsque le changement fonctionnel semble mineur.
• Sensibilité de netlist : de petits refactoring peuvent altérer les décisions de conditionnement, de placement et de congestion de routage.
• Dérive des contraintes : de petits changements XDC (ou manque de couverture) peuvent amplifier la variation de timing.
• Habitudes d'atténuation : mise en œuvre incrémentale, préservation sélective de hiérarchie, et contraintes stables.
Lorsque les équipes adoptent ces habitudes d'atténuation, l'itération tend à sembler plus prévisible, ce qui réduit la tentation de geler la conception prématurément par crainte de briser à nouveau le timing.
Considérations sur la licence
La licence tend à devenir une conversation lorsque un projet rencontre des limites de couverture de dispositif ou lorsque des fonctionnalités avancées sont nécessaires pour un flux de travail particulier.
• Standard : aligne souvent avec des cartes d'apprentissage d'entrée et de milieu de gamme et des flux de base.
• Entreprise : aligne souvent avec un support de dispositif plus large et des capacités avancées.
Pour les équipes, les licences flottantes soutenues par un serveur de licences sont souvent plus faciles à mettre à l'échelle que les licences verrouillées par nœud, surtout lorsque les constructions fonctionnent sur des machines partagées, des serveurs de construction dédiés ou des coureurs CI. De nombreuses équipes préfèrent aligner la licence avec la feuille de route du dispositif plus tôt que plus tard, car les surprises de licence ont tendance à apparaître lorsqu'il est déjà coûteux et politiquement difficile de changer de dispositif.
Une boucle d'ingénierie cohérente tend à prédire un progrès plus régulier qu'une seule optimisation astucieuse : gardez les contraintes alignées avec la réalité, lisez les rapports régulièrement (même lorsque vous préférez ne pas le faire), corrigez les causes profondes au lieu de calmer les symptômes, et rendez les constructions reproductibles. Lorsque cette boucle est établie, Vivado ressemble moins à une boîte noire et davantage à un tableau de bord, et la fermeture temporelle passe d'une pression de dernière minute à quelque chose que l'équipe peut gérer délibérément.
Portefeuille et écosystème Xilinx

Choisir parmi les dispositifs Xilinx tend à se dérouler plus sereinement lorsque le point de départ est l'intégration environnante (processeurs, interfaces mémoire, chemin de démarrage et dépendances au niveau de la carte), pas seulement une comparaison des totaux de LUT bruts. Ce cadre correspond généralement à la manière dont les vrais emplois du temps et les vrais risques se manifestent.
Un FPGA discret tend à convenir lorsque l'équipe souhaite avoir la pleine propriété de l'architecture de la carte et que la charge de travail penche vers un comportement matériel déterministe avec une surface logicielle minimale. Un SoC de classe Zynq tend à convenir lorsque la conception bénéficie d'un CPU proche de la logique d'accélération, de sorte que le contrôle et le chemin de données puissent évoluer ensemble sans transformer la carte en une négociation multi-puces. Un module de type Kria SOM tend à convenir lorsque le plan est d'agir rapidement et de limiter l'incertitude de mise en service de la carte en traitant le calcul, la mémoire et le stockage de démarrage comme un élément de construction pré-qualifié.
Le FPGA discret tend à convenir pour :
• un contrôle maximal de la conception de la carte
• des pipelines déterministes avec une dépendance logicielle limitée
Le SoC Zynq tend à convenir pour :
• un couplage étroit CPU+accélérateur
• un calcul/un contrôle unifié sur un seul dispositif
• une évolution itérative HW/SW
Le Kria SOM tend à convenir pour :
• un temps de mise sur le marché plus court
• une exposition réduite au niveau de la carte en utilisant un sous-système de calcul validé
Les FPGAs simples s'avèrent souvent alors que le problème est motivé par la pression de fermeture temporelle, des besoins d'E/S inhabituels ou des pipelines de streaming qui se comportent mieux en tant que matériel à fonction fixe. Une latence prévisible et des chemins de données structurés améliorent souvent le contrôle, la vérification et le débogage, surtout lorsque l'architecture reste bien organisée.
Les dispositifs autonomes apparaissent fréquemment dans :
• l'interfaçage de capteur
• le contrôle de moteur
• le traitement de paquets à taux modéré
• le pontage de protocoles
Sur le terrain, une source récurrente de frustration n'est pas le RTL lui-même mais les obligations de carte environnantes qui arrivent discrètement et dominent ensuite le chemin critique. Les rails d'alimentation, la stratégie de configuration et de démarrage, la génération d'horloge, la disposition de la mémoire externe (lorsqu'elle est présente) et l'accès au débogage peuvent se transformer en contraintes qui façonnent l'ensemble du produit. Une règle pratique est que plus l'histoire de la mémoire externe est simple et moins il y a de récepteurs à grande vitesse impliqués, plus l'expérience de la FPGA autonome devient satisfaisante. Dès que la DDR externe et les flux de démarrage en plusieurs étapes deviennent inévitables, l'attrait de l'intégration d'un SoC ou d'un module commence à sembler moins comme une fonctionnalité et plus comme un soulagement.
Les familles optimisées en coût visent généralement un mélange mesuré de LUT, BRAM et DSP sous des budgets de puissance restreints. Elles apparaissent beaucoup dans des produits où l'équipe d'ingénierie veut une capacité respectable sans payer le prix de la carte et de la chaleur qui accompagne des interfaces extrêmes.
Les zones d'atterrissage courantes incluent :
• contrôle embarqué
• agrégation d'E/S à moyen terme
• traitement de signal à vitesse modérée
L'avantage n'est pas seulement le prix unitaire, les équipes apprécient souvent que ces pièces facilitent le maintien dans les limites thermiques sans recourir à un refroidissement agressif, et elles peuvent éviter que le PCB ne se transforme en un projet de mise en page à grande vitesse. En même temps, les constructions sur le terrain enseignent régulièrement une leçon légèrement inconfortable : un dispositif moins coûteux peut entraîner une dépense totale plus élevée s'il force des compromis de conception à un stade tardif. Lorsque la marge de timing est mince, de petits ajustements, un changement de norme d'E/S, une modification de routage d'horloge, un changement de plan d'étage, peuvent avoir des répercussions sur le changement de vérification et l'anxiété liée au calendrier. Pour ces dispositifs, les équipes gagnent généralement du temps en fixant tôt la planification de domaine d'horloge, la stratégie CDC et le comportement de réinitialisation, plutôt que d'espérer que de petites micro-optimisations tardives viendront sauver le plan.
SoCs Zynq
Les dispositifs Zynq combinent le traitement ARM avec la logique programmable, ce qui permet à la conception de se diviser en logiciel de plan de contrôle et accélération de plan de données d'une manière qui semble naturelle pour de nombreuses équipes produit. Cela fait plus qu'améliorer la commodité, cela redessine le flux de travail. Les équipes peuvent commencer avec une référence axée sur le logiciel pour avoir confiance en la fonctionnalité, puis migrer les chemins critiques vers le matériel à mesure que les exigences de débit et de latence deviennent moins négociables.
Dans les déploiements qui vieillissent bien, le CPU ne "remplace" que rarement le matériel, il a tendance à stabiliser le produit. Le processeur finit souvent par gérer la configuration, la télémétrie, les mises à niveau, la politique de sécurité et la connectivité en périphérie, tandis que le tissu gère des pipelines déterministes. Cette séparation peut être émotionnellement rassurante pour les responsables de la maintenance : le logiciel absorbe le changement, le matériel reste stable, et les versions ressemblent moins à un jeu de hasard.
Le CPU porte généralement :
• configuration
• télémétrie
• mises à niveau
• politique de sécurité
• connectivité en périphérie
Le tissu porte généralement :
• pipelines de streaming déterministes
• accéléraiteurs stables
• chemins de données sensibles à la latence
À mesure que la densité de calcul augmente et que les interfaces deviennent plus exigeantes, les pièces de type Zynq UltraScale+ réduisent la complexité des cartes et des systèmes en rapprochant les cœurs de CPU, les contrôleurs DDR et les interconnexions haut débit du tissu. Cela devient attrayant dans les conceptions qui nécessitent à la fois un déterminisme en temps réel et un environnement logiciel capable, surtout lorsque la charge de travail est un mélange plutôt qu'un seul noyau propre.
Les cas d'utilisation fréquents incluent :
• analyse en périphérie
• fusion de multi-capteurs
• pipelines temps réel mixtes plus IA
Un détail que les équipes expérimentées apprennent à respecter est que "plus de tissus" ne se transforme pas automatiquement en "plus de performances délivrées". Les projets rencontrent souvent des plafonds de bande passante mémoire avant d'épuiser les DSP ou les LUT. Les conceptions qui décident tôt de la topologie DMA, de la stratégie de mise en tampon et des attentes de cohérence de cache ont tendance à atteindre des performances stables avec moins de remaniement que les conceptions qui différèrent les décisions de mouvement des données jusqu'à une intégration tardive.
La partition concerne rarement la question de savoir si quelque chose pourrait être accéléré, il s'agit plutôt de savoir si l'accélération en vaut la peine compte tenu de l'effort de vérification, de la complexité des pilotes et d'exécution, et de la fréquence à laquelle la logique est censée changer. Les équipes ressentent souvent un tiraillement ici : pousser trop dans le matériel peut ralentir l'itération, tandis que laisser trop sur le CPU peut laisser les objectifs de débit perpétuellement presque atteints.
Les charges de travail qui restent souvent sur le CPU plus longtemps que prévu incluent :
• logique à changement rapide
• comportement complexe et gourmand en analyse
• fonctionnalités avec des cycles d’itération rapides
Les charges de travail qui récompensent souvent une accélération précoce des tissus incluent :
• algorithmes stables
• noyaux denses en calcul
• chemins de données adaptés au streaming
Un schéma pragmatique consiste à commencer par un petit segment de bout en bout, souvent une simple boucle de retour DMA plus un accélérateur minimal, avant de construire l'ensemble de fonctionnalités. Ce prototype limité tend à mettre en évidence les problèmes d'intégration qui arrivent autrement tard et de manière coûteuse : comportement d'interruption, alignement des tampons, coût de maintenance du cache et plafonds de débit qui n'apparaissent que sous charge soutenue.
Kria SOMs et plateformes de type module
Les Kria SOMs emballent le calcul, la mémoire et le stockage de démarrage dans un sous-système prêt à l'emploi, déplaçant l'effort loin de la mise en service de la carte et vers l'ingénierie des applications. Les équipes apprécient souvent cette approche car elle contient de l'incertitude : l'intégrité du signal, le routage DDR, la séquence d'alimentation et la fiabilité de démarrage sont déjà validés, ce qui peut rendre les démonstrations précoces moins fragiles et la planification moins spéculative.
L'approche fonctionne souvent particulièrement bien lorsque la différenciation se trouve dans les algorithmes, la topologie I/O et la fiabilité de déploiement plutôt que dans une carte de calcul personnalisée. Elle peut également réduire les frictions entre les équipes : le travail matériel, le firmware et les applications peuvent avancer en parallèle avec moins de moments "bloqués par la mise en service".
L'intégration validée des SOM couvre généralement :
• intégrité du signal
• routage DDR
• séquence d'alimentation
• fiabilité de démarrage
Les équipes peuvent recentrer leurs efforts sur :
• différenciation des cartes porteuses
• intégration de firmware
• comportement d'application
• renforcement du déploiement
Un SOM a souvent un coût unitaire plus élevé qu'une carte entièrement personnalisée, mais le coût total du programme peut encore diminuer lorsque les délais sont serrés ou que le risque de rendement de fabrication est inconfortable. Le gain moins évident est la prévisibilité du cycle de vie : avec un module, le calcul peut parfois être traité comme un élément interchangeable à travers les variantes de produits, réduisant le renouvellement de conception lorsque les exigences changent en cours de route.
La démarche la plus rassurante est de valider tôt que la marge thermique, l'exposition I/O et la bande passante mémoire du SOM correspondent réellement à la charge de travail envisagée, plutôt que de se fier à la lecture d'une fiche technique. Si l'application se retrouve limitée par la bande passante, le réglage tardif a tendance à ressembler à une poussée contre une porte verrouillée, le décalage entre la demande d'accélérateur et le sous-système mémoire du module domine simplement.
Les vérifications de conformité précoce comprennent généralement :
• enveloppe thermique
• I/O exposé
• bande passante mémoire soutenue versus demande de charge de travail
Déploiement de l'IA dans l'écosystème
Vitis AI aide à convertir des modèles entraînés en conceptions d'inférence basées sur FPGA en utilisant des formats de précision inférieure, souvent INT8, et les compile pour des architectures de type DPU. Cela confirme rapidement si un modèle peut fonctionner sur la plateforme FPGA. Cependant, la performance réelle dépend souvent fortement de la conception du système environnant, en particulier du mouvement des données et de la gestion de la mémoire.
Le débit de bout en bout est généralement gouverné par la manière dont le système peut alimenter de manière cohérente le DPU. La stratégie de lot, la disposition des tenseurs, la planification DMA, le double tampon et le placement de la mémoire décident souvent des FPS fournis plus que le calcul en tête d'affiche. Les équipes qui traitent le DPU comme un consommateur de flux constant, avec des tampons soigneusement organisés, tendent à éviter la déception courante d'un TOPS théorique impressionnant mais des résultats au niveau système décevants.
Les boutons de réglage de performance incluent couramment :
• stratégie de lot
• disposition des tenseurs
• planification DMA
• double tampon
• placement de la mémoire
Dans les déploiements, de petits choix d'implémentation s'additionnent de manière à être difficiles à prédire à partir de microbenchmarks en laboratoire. Des tampons mal alignés peuvent réduire discrètement la bande passante effective. Un entretien excessif du cache peut absorber du temps CPU et créer des variations. Des pipelines chargés de copies peuvent effacer une grande partie des avantages obtenus grâce à la quantification. Une approche réaliste consiste à mesurer la bande passante et la latence à chaque frontière, puis à concentrer les efforts sur la frontière qui est actuellement la plus étroite.
Les frontières de mesure utiles incluent :
• capteur à DDR
• DDR à accélérateur
• accélérateur à post-traitement
Un modèle mental utile est de voir le pipeline d'IA comme un réseau de flux contraint. Avec ce cadre, le choix de l'appareil devient moins une question de poursuivre le plus grand nombre de calcul et plus une question de choisir l'option qui relâche le goulet d'étranglement dominant et maintient le comportement du pipeline prévisible.
Écosystème et facilitation
L'écosystème Xilinx s'étend au-delà du silicium vers la facilitation environnante qui maintient les équipes en mouvement : chaînes d'outils, IP, conceptions de référence, cartes partenaires et ressources de formation. Dans les établissements académiques, le programme universitaire est souvent apprécié car il réduit la douleur de configuration récurrente, l'accès aux outils, la disponibilité des cartes et la structure du laboratoire, si bien que les progrès préalables sont moins susceptibles de stagner à cause de problèmes d'environnement plutôt que d'apprendre l'ingénierie réelle.
Les composants de l'écosystème incluent :
• chaînes d'outils (Vivado, Vitis)
• catalogues IP
• conceptions de référence
• cartes partenaires
• programmes de formation
• ressources du programme universitaire
Une fois que la friction d'intégration est réduite, les apprenants peuvent dépenser leur énergie sur les habitudes qui se traduisent directement par un travail professionnel : routines de fermeture temporelle, discipline de pipelining, stratégie de vérification et jugement de co-conception matériel/logiciel. Ces compétences ont tendance à montrer leur valeur lors de l'intégration, lorsque les résultats sont façonnés davantage par la vitesse d'itération et la cohésion du système que par un benchmark de noyau isolé.
Les compétences transférables incluent :
• habitudes de fermeture temporelle
• discipline de pipelining
• stratégie de vérification
• co-conception matériel/logiciel
Un principe de sélection qui reste cohérent dans l'ensemble
Une approche de sélection fiable part des contraintes du système plutôt que des niveaux de marketing. Les équipes obtiennent généralement des décisions plus claires lorsqu'elles écrivent les objectifs d'exploitation et les réalités du projet à l'avance, puis choisissent le niveau d'intégration, FPGA, Zynq SoC ou SOM, qui réduit les plus grandes sources d'incertitude pour leur programme spécifique. Cela tend à produire des choix qui semblent meilleurs des mois plus tard, lorsque le rythme d'intégration et d'itération compte plus qu'une comparaison de pièces sur le papier.
Les contraintes à définir tôt incluent :
• objectifs de latence
• besoins en bande passante soutenue
• exigences d'interface
• limites thermiques
• cadence de mise à jour
• budget de vérification
Dans de nombreux programmes, l'option qui maintient le mouvement des données simple et la boucle de développement serrée finit par être celle qui vieillit le mieux, même si son prix unitaire n'est pas le plus attrayant à première vue.
Conclusion
Apprendre la conception FPGA Xilinx devient plus facile lorsque chaque projet suit un processus stable et répétable. De bons résultats dépendent d'un HDL propre, de contraintes correctes, de vérifications minutieuses du timing, de simulations et de validation sur matériel réel. En commençant par des conceptions simples et en développant de bonnes habitudes de débogage, les débutants peuvent acquérir des compétences FPGA fiables pour des systèmes numériques plus avancés.
Questions Fréquemment Posées [FAQ]
1. Pourquoi les débutants en FPGA ont-ils souvent du mal même lorsque leur code HDL semble logiquement correct en simulation ?
De nombreux problèmes FPGA précoces ne sont pas causés par le RTL lui-même, mais par l'écart entre les hypothèses de simulation et le comportement physique du matériel. La simulation masque généralement les problèmes liés aux contraintes d'horloge, au timing de réinitialisation, aux normes d'E/S, à la métastabilité et à la fermeture temporelle. Un design peut simuler parfaitement tout en échouant sur le matériel parce que les outils FPGA interprètent les horloges différemment, que les contraintes sont incomplètes, ou que les entrées asynchrones sont mal gérées.
2. Pourquoi les contraintes temporelles sont-elles considérées comme une partie essentielle de la conception FPGA au lieu d'une étape d'optimisation finale ?
Les contraintes temporelles définissent comment les outils FPGA interprètent les horloges, les relations de timing des E/S, les horloges générées et les domaines asynchrones. Sans contraintes précises, Vivado peut optimiser le design en utilisant des hypothèses incorrectes, ce qui entraîne des rapports de timing trompeurs et un comportement matériel instable. De nombreux échecs FPGA se produisent même lorsque la logique elle-même est correcte parce que les horloges n'ont pas été déclarées correctement, que le timing des E/S a été ignoré ou que des exceptions ont été appliquées de manière trop large. En pratique, les contraintes agissent comme une description formelle de l'intention de conception, permettant aux outils de construire un matériel correspondant au comportement électrique réel.
3. Pourquoi le débogage FPGA nécessite-t-il souvent à la fois des simulations et des outils embarqués comme l'ILA ?
La simulation est très efficace pour détecter les bogues fonctionnels, mais elle ne peut pas reproduire pleinement les effets réels du matériel tels que le jitter, les entrées asynchrones, les retards au niveau de la carte, la métastabilité et la variation d'alimentation. Les outils de débogage embarqués comme l'Analyseur Logique Intégré (ILA) fournissent une visibilité sur les signaux internes du FPGA pendant que le système fonctionne dans des conditions réelles. Cela permet de capturer des transitions d'état réelles, le comportement FIFO, les échanges et les relations de timing directement à l'intérieur de l'appareil. Combiner la simulation avec le débogage ILA crée une compréhension plus complète des raisons pour lesquelles le matériel s'écarte du comportement attendu.
4. Pourquoi les ingénieurs FPGA expérimentés préfèrent-ils des flux de travail disciplinés et répétables plutôt que des configurations de projet constamment changeantes ?
Les flux de travail répétables réduisent l'incertitude et facilitent l'isolement des échecs. Utiliser la même carte de développement, la même structure d'horloge, la même stratégie de réinitialisation et le même modèle de projet permet aux ingénieurs de se concentrer sur la logique développée plutôt que de déboguer sans cesse l'environnement lui-même. Les projets FPGA impliquent de nombreuses variables interactives, notamment les contraintes, l'horloge, le comportement de synthèse et la configuration au niveau de la carte. Lorsque trop de variables changent simultanément, le débogage devient imprévisible et émotionnellement épuisant. Des flux de travail stables améliorent la confiance car les changements peuvent être retracés à des décisions de conception spécifiques plutôt qu'à des différences environnementales inconnues.
5. Pourquoi la conception matérielle FPGA est-elle fondamentalement différente de la programmation logicielle traditionnelle ?
Le logiciel exécute des instructions de manière séquentielle, tandis que le matériel FPGA fonctionne à travers des structures logiques concurrentes s'exécutant simultanément. HDL décrit le comportement physique du matériel plutôt que le flux d'exécution procédural. Les débutants s'attendent souvent à un comportement semblable à celui du logiciel, puis deviennent confus lorsque plusieurs blocs matériels réagissent en parallèle au même bord d'horloge. La conception FPGA met donc l'accent sur les pipelines, les relations de timing, la synchronisation, le mappage des ressources et le comportement des domaines d'horloge plutôt que sur l'ordre des instructions uniquement. Comprendre la concurrence est l'un des changements mentaux les plus importants en ingénierie FPGA.
6. Pourquoi de petits changements RTL peuvent-ils soudainement provoquer d'importants problèmes de fermeture temporelle dans les projets FPGA ?
Le comportement temporel FPGA dépend fortement du placement, de la congestion de routage, du fan-out, des relations d'horloge et de l'utilisation des ressources physiques. Même de petites modifications RTL peuvent modifier la façon dont les outils de synthèse et de routage mappent la logique à travers le dispositif. Un changement apparemment inoffensif peut augmenter la pression de routage, allonger les chemins combinatoires ou affecter les décisions de placement de manière à réduire significativement la marge de timing. Cette sensibilité devient plus sévère à mesure que l'utilisation augmente, en particulier lorsque les conceptions approchent des limites de routage ou d'horloge.
7. Pourquoi les projets FPGA deviennent-ils fréquemment contraints par des réalités au niveau de la carte plutôt que par la complexité du RTL seul ?
À mesure que les systèmes FPGA se développent, les défis liés au séquençage de l'alimentation, à la disposition DDR, à la génération d'horloge, au comportement thermique, à l'intégrité des signaux et au routage des transceivers dominent souvent le temps de développement. Le RTL peut fonctionner correctement tandis que l'infrastructure matérielle environnante introduit des instabilités ou des échecs d'intégration. Les ingénieurs découvrent souvent que les décisions de conception de la carte, le séquençage des réinitialisations et le comportement de l'interface mémoire façonnent le succès global du projet plus que le HDL lui-même. Cela est particulièrement vrai dans les systèmes à grande vitesse utilisant de la mémoire DDR externe et des interfaces SERDES.
8. Pourquoi de nombreuses équipes FPGA évaluent-elles les chaînes d'outils aussi sérieusement que le matériel FPGA lui-même ?
La chaîne d'outils FPGA affecte directement le temps de compilation, la stabilité de la fermeture temporelle, l'efficacité du débogage, l'intégration CI et la productivité globale en ingénierie. Des résultats d'implémentation lents ou inconsistants peuvent augmenter considérablement le temps d'itération et la pression sur le calendrier. Les équipes évaluent souvent la qualité de synthèse, la clarté des rapports de timing, l'instrumentation de débogage et la reproductibilité avant de s'engager sur une plateforme. Dans de réels environnements de développement, des builds prévisibles et une fermeture temporelle stable comptent souvent plus que des spécifications FPGA isolées en tête d'affiche.
9. Pourquoi les SoCs Zynq et les plateformes Kria SOM réduisent-ils la complexité d'intégration par rapport aux FPGAs autonomes ?
Les SoCs Zynq combinent des processeurs ARM et de la logique programmable au sein d'un même appareil, simplifiant la communication entre le logiciel et l'accélération matérielle. Les Kria SOM vont plus loin en intégrant de la mémoire, du stockage de démarrage, de la séquence d'alimentation et du matériel validé dans un module préqualifié. Ces approches réduisent les risques associés au routage DDR, à la fiabilité de démarrage, à la conception de la livraison d'énergie et à la mise en route de la carte. En conséquence, les équipes peuvent se concentrer davantage sur le comportement des applications et moins sur les défis d'intégration matérielle de bas niveau.
10. Pourquoi le déploiement réussi de l'IA basé sur FPGA dépend-il fortement du mouvement des données plutôt que de la seule performance de l'accélérateur ?
Les accélérateurs IA tels que les DPU peuvent fournir un débit de calcul théorique élevé, mais la performance dans le monde réel est souvent limitée par la bande passante mémoire, la planification DMA, la gestion des tampons et l'efficacité du mouvement des tenseurs. Des pipelines de données mal optimisés peuvent affamer l'accélérateur et réduire considérablement le FPS effectif malgré une forte capacité de calcul. Les systèmes d'IA FPGA réussis se concentrent donc fortement sur le double-bufférisation, la topologie DMA, la stratégie de regroupement, le placement de la mémoire et un flux de données soutenu entre les capteurs, la mémoire DDR, les accélérateurs et les étapes de post-traitement.
Blog connexe
-
Combien de zéros dans un million, des milliards de milliards de billions?
![Combien de zéros dans un million, des milliards de milliards de billions?]()
2024/07/29
Des millions représentent 106, un chiffre facilement saisissable par rapport aux articles quotidiens ou aux salaires annuels. Milliards, équivalent ... -
Fiche technique MOSFET IRLZ44N, circuit, équivalent, épingle
![Fiche technique MOSFET IRLZ44N, circuit, équivalent, épingle]()
2024/08/28
L'IRLZ44N est un MOSFET de puissance à nailaux N largement utilisé.Renommé pour ses excellentes capacités de commutation, il est très adapté à ... -
Température de la batterie trop basse, la charge s'est arrêtée.Comment le réparer?
![Température de la batterie trop basse, la charge s'est arrêtée.Comment le réparer?]()
2024/10/6
Les problèmes de charge de batterie de téléphone portable sont courants mais peuvent être gérés efficacement.La température joue un rôle impor... -
BC547 Guide complet du transistor
![BC547 Guide complet du transistor]()
2024/07/4
Le transistor BC547 est couramment utilisé dans une variété d'applications électroniques, allant des amplificateurs de signal de base aux circuits... -
Guide complet du SCR (redresseur contrôlé en silicium)
![Guide complet du SCR (redresseur contrôlé en silicium)]()
2024/04/22
Les redresseurs contrôlés en silicium (SCR), ou thyristors, jouent un rôle central dans la technologie de l'électronique de puissance en raison de... -
LR621, SR621SW, 364, équivalents de batterie AG1 et remplacements
![LR621, SR621SW, 364, équivalents de batterie AG1 et remplacements]()
2024/07/15
Les batteries de bouton LR621 et SR621SW sont répandues dans des appareils électroniques compacts comme les montres, les petits jouets, les calculat... -
Un guide complet des multiplexeurs et leur rôle dans les systèmes numériques
![Un guide complet des multiplexeurs et leur rôle dans les systèmes numériques]()
2025/09/20
Les multiplexeurs sont des composants des systèmes numériques, conçus pour canaliser plusieurs signaux d'entrée dans une seule ligne de sortie en ... -
Fondamentaux des circuits d'amplificat
![Fondamentaux des circuits d'amplificat]()
2023/12/28
Dans le monde complexe de l'électronique, un voyage dans ses mystères nous conduit invariablement à un kaléidoscope de composants de circuit, à l... -
Comparaison des différences et applications des NMOS et PMO
![Comparaison des différences et applications des NMOS et PMO]()
2024/11/15
Comprendre les différences entre les transistors NMOS et PMOS est important pour concevoir des circuits efficaces.Les NMOS (N-Type Metal-Oxide-Semico... -
CR2450 vs CR2032 Comparaison: tout ce que vous devez savoir
![CR2450 vs CR2032 Comparaison: tout ce que vous devez savoir]()
2025/09/15
Les batteries de bouton comme CR2450 et CR2032 alimentent de nombreux appareils électroniques de tous les jours, des montres et télécommandes aux d...










Pièces chaudes
- MC908GP32CFBE
- RL1218FK-070R068L
- RT1206DRD0730KL
- STM8L051F3P6TR
- V375B48C300AN
- AN41241A
- PMBT2222A
- AD7835AP
- ERJ-3GEYJ223V
- R2A20273FT
- P87LPC764FD
- W25P243AF-4S
- IR21367S
- EP3SE50F780I3
- INL837GN
- PCA9543APWR
- ATMXT1668T2ES-CCU
- AD5201BRM50-REEL7
- DF50-20DP-1H(51)
- PIC18F65K80-I/PT
- LM4819MM/NOPB
- PIC12F1572-I/MS
- AD8008ARM-REEL
- TPSD226K025H0100
- MT79332
- BCM4350KWBDCG
- TAP685K010BRW
- 12061A101KAT2A
- VI-J5V-01
- CGA3E3X5R1A225K080AB
- MST9883B-C-LF-110
- QMK432B7224MMHT
- TLC073IDGQR
- 06031A0R8CAT2A
- TJA1024HGZ
- LB8115W-NA-TLM-E
- MAX2463EAI
- ADG822BRMZ-REEL7
- CY7C1019CV33-15VCT
- V375A24C600BN4
- AD536AJD
- AD9398XSTZ-150
- VI-244-MW
- VI-JW4-MZ
- VI-J71-IZ
- BWR-12/125-D12-C
- RMPA0913B
- IS61WV102416BLL-10TL
- M80C86A-2JS
- CYW88373CUBGT